As a developer or architect, you must have faced the challenge of slow loading times and sluggish performance in your applications. As your user base grows, the challenge only gets bigger.
Distributed caching can help you scale your application and speed up data retrieval.
In this introduction post, I will take you through the what, why, where and how of distributed caching so that you can try out this fantastic tool in your next big project.
In case you want a more basic overview, you can also refer to this post about caching in general and then return to this post.
1 – What is Distributed Caching?
Imagine being able to access your favourite social media profile or online shopping cart at lightning speed, without any delays or lag. This is the power of distributed caching!
Distributed caching is a revolutionary technique where data is strategically stored in multiple locations, typically across a network of computers, to boost the performance and scalability of a system.
Think of it as creating multiple copies of your data and placing them in different locations so you can easily access them when needed.
Are you looking for some real examples? Here is a couple of them:
- A popular e-commerce website might use distributed caching to store frequently accessed product information in memory, so it can be retrieved instantly instead of having to fetch it from a database. This can greatly improve the user experience, as pages load faster and shopping carts can be updated in real-time.
- Similarly, a social media platform might store its most popular profiles in a distributed cache, ensuring that posts made from these profiles are instantly loaded. After all, these are the profiles that bring maximum traffic to the platform.
In a nutshell, distributed caching is the secret sauce behind the seamless and smooth performance of some of the most popular websites and apps that you are using in your daily lives.
2 – Why Distributed Caching is so popular?
Two of the biggest players in the distributed caching ecosystem are Redis and Memcached.
According to this report by Facebook, they have utilized Memcached as a primary building block to construct a distributed key-value store to support the world’s largest social network.
Over the years, Redis has also seen widespread adoption in the industry. According to the Redis website, more than 10K companies are using the Redis platform to handle their data needs.
But what makes distributed caching so popular?
Distributed caching provides several benefits that make it such a natural choice for organizations with extreme data needs.
Let’s look at a few of them:
Scalability
When a website or application becomes more popular, it means more users are trying to access it at the same time.
This can potentially put a lot of strain on a single server and cause it to become slow or even crash.
Distributed caching helps to spread the load across multiple servers. This makes the system more scalable since it can handle a larger number of users with the same amount of resources.
Performance
Distributed caching stores frequently accessed data in memory.
We all know that memory is much faster to access than traditional disk-based storage.
This means that data from a distributed cache can be retrieved almost instantly, improving the overall performance of the system.
High Availability
As the name implies, a distributed cache replicates data across multiple servers.
This means that even if one server goes down, you can still access the data. Just by utilizing a distributed cache, your system is more available and less vulnerable to data loss.
Fault Tolerance
This benefit has got more to do with the implementation of distributed caching systems.
For example, distributed caching systems (such as Memcached and Redis) have built-in fault tolerance mechanisms that can automatically detect and recover from failures.
This improves the reliability of the system and minimizes any potential downtime.
Ease of Use
It might sound surprising, but distributed caching systems are designed to be easy to use and manage.
Imagine you have to write the entire logic for data distribution and replication. It would take so much of your bandwidth.
With an enterprise-grade caching system, you get these services for free so that you can focus on writing your actual business logic.
3 – Distributed Caching Use Cases
With a bunch of super-cool benefits, the case for distributed caching appears quite strong.
But what are some practical areas that can benefit from distributed caching?
Here are a few popular use cases of distributed caching:
Content Delivery Networks or CDNs
CDNs are quite commonly used these days to improve your website’s performance and reduce the load on the origin server.
You typically use CDNs to store web content such as images and videos. Sometimes, entire websites are delivered via a CDN.
Under the hood, CDN providers utilize distributed caching for the storage and delivery of content from servers spread across multiple geographic locations. This means that even if your website is hosted in a particular region of the world, you can give a good experience to users across the globe.
Social Media Platforms
Social media platforms such as Twitter or Instagram have millions of users. But not all users have the same kind of following.
If you are a social media platform that hosts Cristiano Ronaldo’s account which has millions of followers and receives a constant barrage of traffic, you want to make sure that the profile is always available. You can’t afford to anger so many users at one go.
Using a distributed caching system to store highly important and popular profiles, posts and comments can improve the performance of your application where it matters the most. After all, happy users mean good business.
E-Commerce Websites
Just like social media, e-commerce websites are prime candidates for using distributed caching.
Think of Amazon hosting a Black Friday Sale only for its servers to crash and burn because of a huge number of users. It would be a scandal of epic proportions. Not to mention the unimaginable loss of revenue.
If you were running Amazon, you’d make sure to utilize something like distributed caching to store the most popular products, reviews and pricing data so that you can provide a seamless shopping experience to as many users as possible.
4 – Distributed Caching System Design
I hope by now you are pretty well aware of the what, why and where of distributed caching.
It is time to look at the how.
A typical distributed caching system design consists of a number of components. Here’s a high-level illustration that depicts things visually.
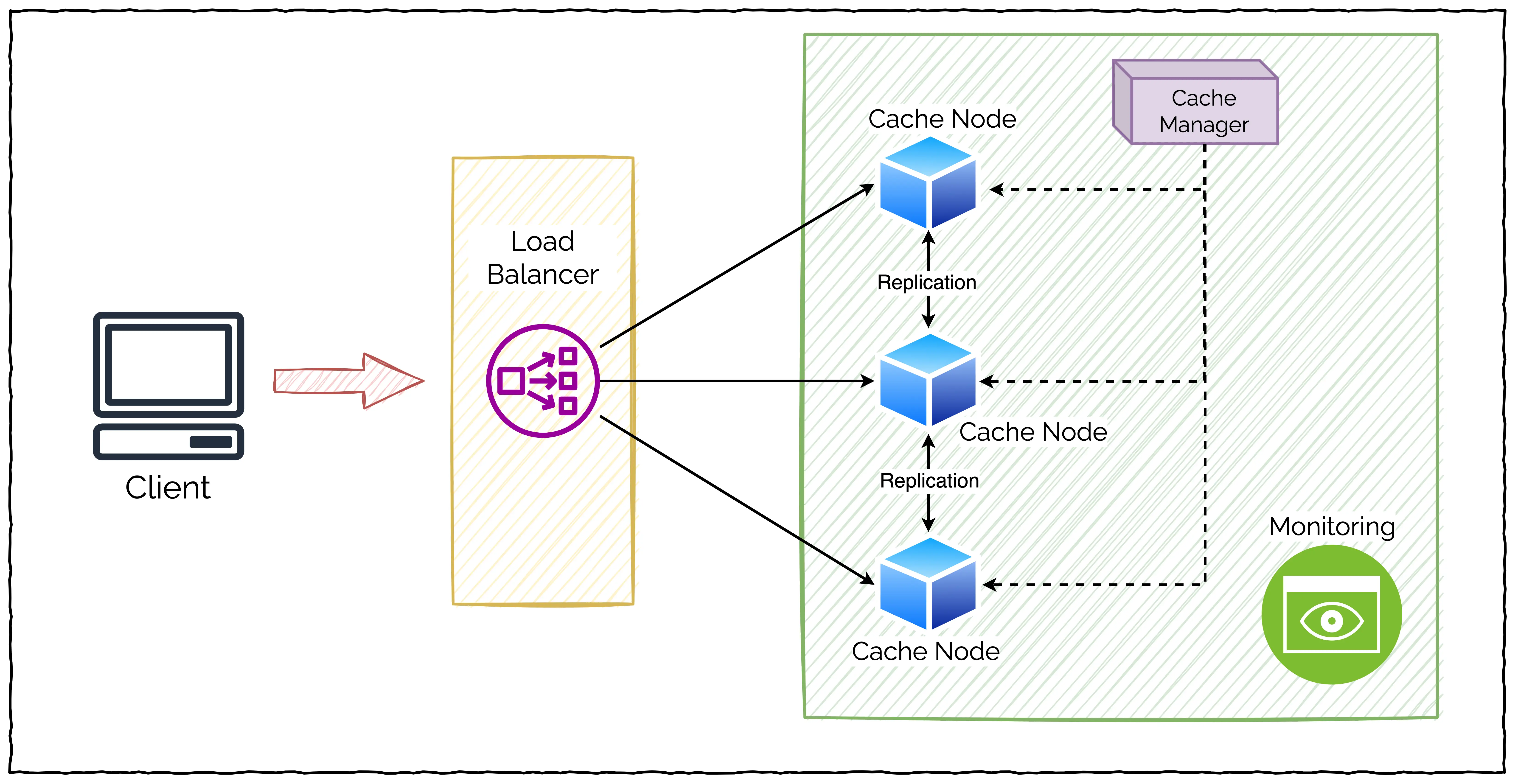
Let’s look at the various components one by one.
Client
This is probably the simplest to understand. A client is basically the application that communicates with the cache.
It can be a web application, a mobile app or even a simple backend service. If you go deeper, a client can also be a custom-built application or a third-party library that acts as a middleman between the real application and the distributed cache.
Ultimately, a client’s job is to send a request to the cache and receive some data.
Cache Nodes
Cache nodes are servers that store the cached data.
Since we are considering distributed caches, these nodes can be located in different geographic locations. Or each node may be storing some different type of data.
Think of these nodes as identical servers working in tandem to deliver the service of a distributed cache. If you are using something like Redis, these are basically Redis servers.
Cache Manager
There would always be a manager. No matter how flat the hierarchy is.
The same is true for a distributed cache.
Basically, the cache manager’s job is to — you guessed it — manage the cache nodes. This can mean adding or removing nodes, replicating data across nodes and handling data eviction functionality.
In the context of Redis, this role can be played by the built-in Redis Sentinel or Redis Cluster.
Load Balancer
You don’t want to burden a single node with all the requests as it will negate the benefits of a distributed cache.
The job of a load balancer is to distribute incoming requests to the cache nodes. It can use different algorithms such as round-robin, least connections and so on to determine which node should handle a particular request.
In a typical system, you can use a third-party load balancer such as HAProxy or nginx.
Services for Data Replication or Data Partitioning
The success of a distributed caching system depends on how well it can manage the data.
An ideal caching system should provide services for managing replication and partitioning.
For example, you can configure Redis to automatically replicate data across multiple cache nodes. It can also partition data if needed.
Monitoring
Murphy’s law states that if something has to go wrong, it will. You don’t want it to happen at the worst possible time. And for that, you need to be alert for signs of problems.
A distributed caching system should be constantly monitored.
Without this, it would be a nightmare for administrators to take necessary action when something really goes wrong.
Conclusion
In this post, I have covered the basics of distributed caching, its benefits, use cases and a high-level system design.
As a developer or an architect, distributed caching is a must-have in your toolkit.
From my own experience, I can attest to the impact of distributed caching on an application’s performance. Scalability alone is worth the price of investing in a distributed cache. We have already seen how tricky scalability can be if not managed properly.
Whether you are planning to build a new system or enhance an existing one, distributed caching is worth exploring.
If you liked this post or found it useful, consider sharing it with friends and colleagues.
0 Comments