If you are a doctor treating a patient and want access to her medical record, you’d want the details to be available at all times.
If it’s an emergency case, there can be absolutely no slippage. The data should be highly-available as it might be a matter of life and death.
To simplify the concept, high-availability is a system’s availability to remain operational and accessible for long periods of time with minimal downtime (if any).
And yes, there can still be downtime. There is no such thing as a 100% availability.
However, the downtime should be minimal enough to not cause an impact on the type of application involved.
This is easier said than done.
You can make the application highly-available with multiple instances. But if your database still resides on a single node, you are in a vulnerable situation.
To make it work, your database should also be highly-available.
In this post, I’ll walk you through the different factors that impact the high-availability for databases.
Factors to Achieve High Availability in Databases
There are two main factors that control high availability for a database.
- Redundancy
- Isolation
Redundancy is managed by duplicating the database components.
Isolation is achieved by placing the redundant components in independent hosts in preferably different geographic locations.
Let’s look at both of these factors one by one.
Redundancy
Redundancy is all about having options.
If you’ve one database server and it goes down, that’s the end of the show.
Good bye, go home! Game over!
Clearly, no business looking to thrive would want to be knocked off by a database going down. A study claims that the cost of a database outage is an average of $7900 per minute.
Many businesses wouldn’t be able to survive the shock.
Therefore, aiming for redundancy is a natural choice.
But don’t mistake redundancy for backups.
Backups are more about keeping a copy of the data safe in case of catastrophic loss.
If your one and only server goes down and you’ve got a backup, it’s still going to cost your business big time to make the data from the backup available.
Plus, there are chances that the backup is way behind the actual copy so you might have to deal with data loss.
What businesses actually want is multiple database instances working closely together such that the user still thinks it’s just one database instance.
There are 3 main patterns that can provide this capability.
1 – Active-Passive
When developers start looking for high-availability database setups, most of them start with the Active-Passive approach.
Also, most never go beyond this approach because it easily solves the high-availability requirements of most software systems.
Here’s what it looks like:
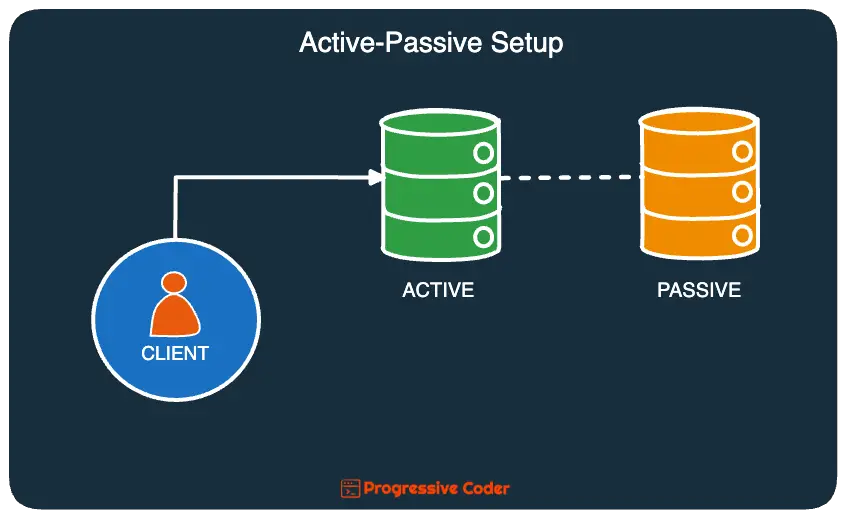
In an active-passive approach, all incoming traffic is routed to the active replica.
A standby node (also known as a passive node) is always ready to go in case the active node goes down for whatever reason.
Data is continuously replicated to the passive node. This replication process can take place synchronously or asynchronously.
There’s a variant of this setup where you can also have the passive node serve reads but the writes are almost exclusively handled by the primary active node.
No matter the case, there are a few major downsides to this approach:
- When you choose asynchronous replication, there’s no guarantee that data is successfully replicated to the passive node. In other words, you need to accept eventual consistency or even data loss.
- If you choose synchronous replication, you’re sacrificing availability even when the passive node goes down.
2 – Active-Active
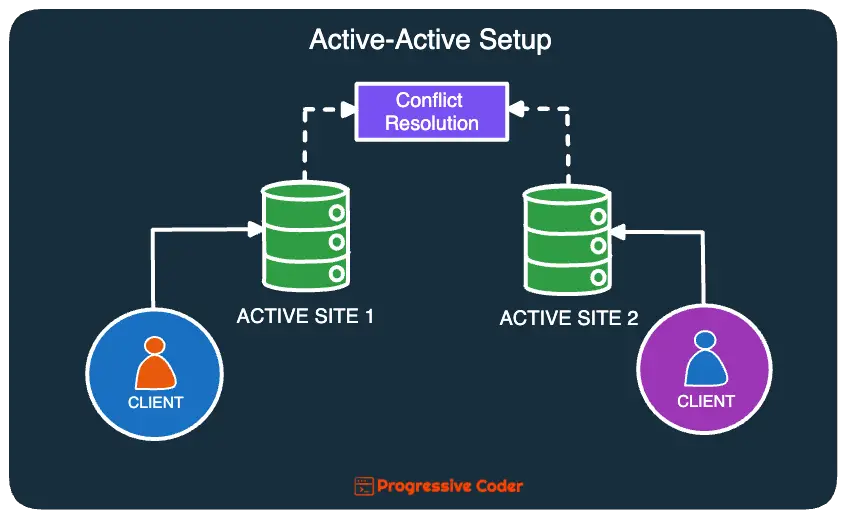
In an active-active setup, multiple replicas are created and traffic is routed to all of them.
If any replica fails, the others handle its share of the traffic.
For a database running in an active-active setup with two nodes, it also means that all nodes can accept both read and write requests.
When a node received a write, it would propagate the changes to the other node.
But such an arrangement can also result in conflicts. For example:
- Consider that we have 2 nodes A and B.
- Node A receives a write for key ‘foo’ and value ‘123’ but it immediately fails.
- B received a read of key ‘foo’ and returns a NULL because it cannot find the key.
- B then receives a write for key ‘foo’ of ‘456’.
- Now A comes back to life and attempts to join with B. At this point, both of them see a conflict for key ‘foo’. There’s inconsistency in the system.
At this point, some sort of conflict resolution algorithm (such as Last Write Wins or Vector Clock) needs to kick in and decide what version of the data should be kept.
As you can see, conflict resolution is not a trivial issue.
Here’s what the active-active setup looks like in practice:
3 – Multi-Active
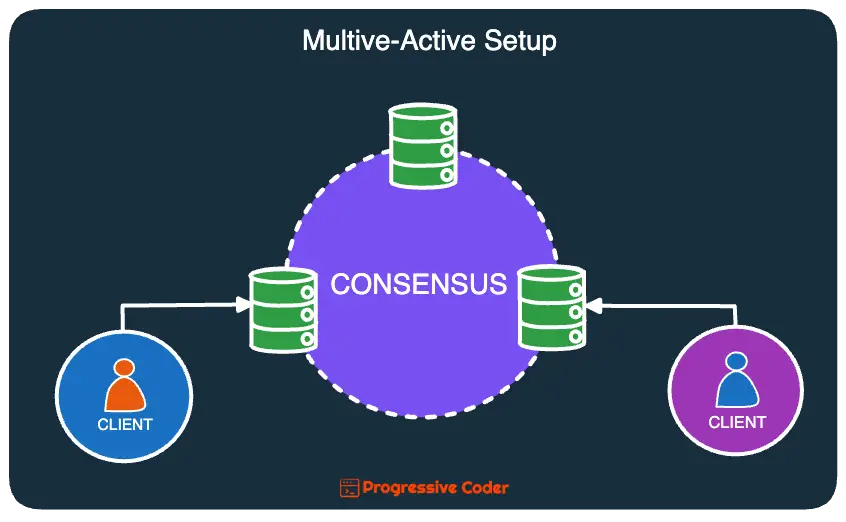
To counter the problems with active-passive and active-active setups, an alternative is to go for multi-active.
In this approach, all replicas can handle read and write requests. However, it follows a consensus-driven approach.
For example, if a replication request is sent to 3 replicas, it is only considered committed when a majority of replicas acknowledge the request. This means that you can have failing nodes in your cluster but it does not compromise on availability like the active-passive approach.
Also, to prevent conflicts and guarantee consistency, clusters that lose a majority of replicas stop responding. That’s because they cannot arrive at a consensus.
Here’s a scenario that will make things clear:
- Consider there are 3 nodes A, B, C.
- A receives a write for key ‘foo’ with a value of ‘123’. It communicates this write to nodes B and C. Both confirm that they’ve received the write. Once A receives the confirmation, the change is committed.
- Now A fails for whatever reason.
- B receives a read for key ‘foo’. It responds with the value ‘123’. No problems over here.
- C receives an update for key ‘foo’ to value ‘456’. It communicates this write request to node B, who acknowledges the request. After receiving the confirmation, the change is committed.
- A is restarted and rejoins the cluster. It receives an update that the new value of key ‘foo’ is ‘456’.
Here’s what this approach looks like:
Isolation
While redundancy patterns solve the major problem in provisioning a high-availability database, we also need to consider the isolation factor.
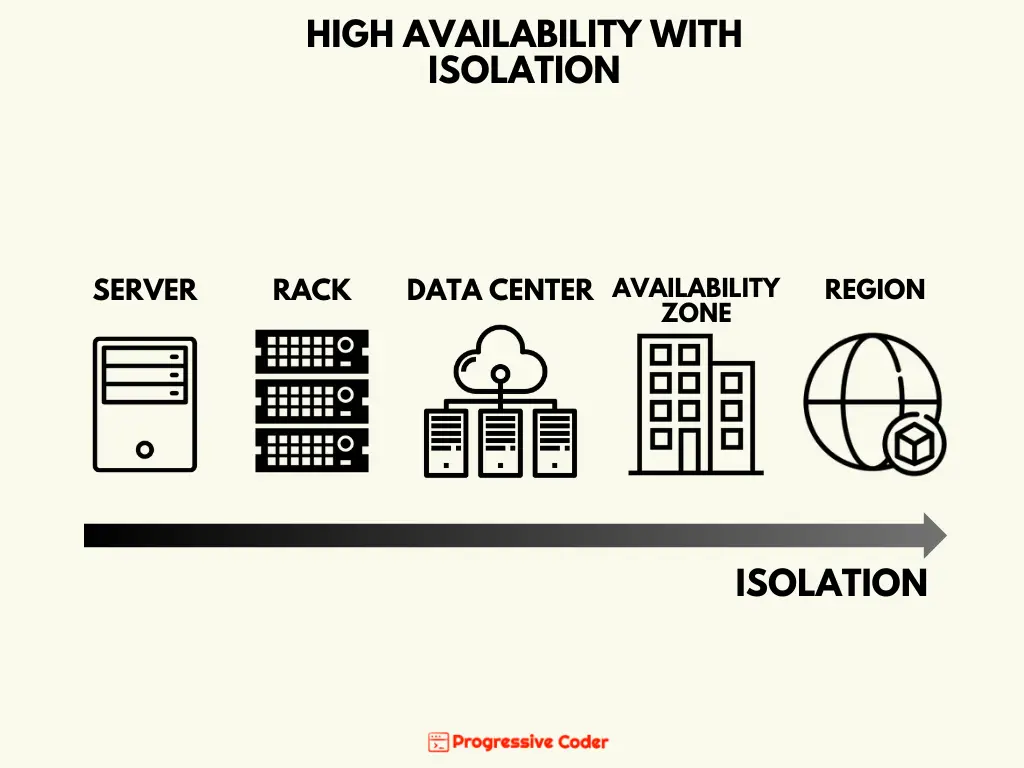
Isolation is all about reducing the impact radius of a disaster on your database system. The more physically separated your redundant components are, the less likely that all of them will fail at the same time.
Here are the various degrees of separation you can opt for:
- Server – Placing redundant components on different servers saves it from storage or CPU failures on one server.
- Rack – The next level of separation can be done at the rack level (a standard enclosure to mount servers). Servers in a rack share a number of elements like network switches and power cables.
- Data center – Data centers share power and cooling infrastructures. You can deploy your database replicas on different data centers making them resilient to events like power failures or accidents.
- Availability Zone – An availability zone consists of one or more data centers that are geographically close to each other but don’t share infrastructure. Deploying across multiple availability zones can protect your database from localized natural disasters like floods or fires.
- Region – The highest level of isolation comes in the form of global regions. A multi-region application can stay safe from major disasters like storms, volcanic eruptions and even political situations like wars.
The below illustration explain the same concept.
Conclusion
That’s all for this post.
We discussed the two main factors for high-availability databases and how you can bring those factors in play to make your database highly-available.
If you have any comments or queries, please mention them in the comments section below.

0 Comments