At face value, Docker, Kubernetes and OpenShift don’t appear to be related. Other times, they appear to be competing with each other. Docker vs Kubernetes. Kubernetes vs OpenShift. These debates often come up from time to time. However, in reality, these three platforms come together in wonderful harmony. The hidden relation between Docker, Kubernetes and OpenShift make it possible to build enterprise-level cloud applications using a vast array of cloud-native technologies.
Despite their apparent relation, developers often don’t realize it while working on one platform. This leads to some problems when they work on day-to-day tasks on these platforms such as:
- Developers are not able to use their knowledge about one platform effectively when working on another platform
- In case of some basic understanding, they are not entirely clear about the boundaries of each of these platforms
- Since Docker, Kubernetes, and OpenShift appear unrelated, they end-up thinking that focusing on learning one of them will block them out of learning the other.
In this post, we will look at the hidden relation between Docker, Kubernetes and OpenShift that you as a developer can make use of. We will understand what these platforms mean individually and how they come together. We will also look at what Docker vs Kubernetes and Kubernetes vs OpenShift really mean.
Let’s start with Docker.
What is Docker?
Docker has been and still continues to be one of the most exciting technologies of this decade.
But what exactly is Docker?
In a nutshell, it is a container technology allowing developers to package their application and its dependencies into a bundle. This bundle is also referred to as a container. This container is largely self-sufficient and can be deployed on different platforms. Essentially, the bundle should run the same wherever it is deployed.
This alleviates a great many problems around implementing new software into production. Often, you would have heard developers complaining that what worked perfectly fine in development or staging environment didn’t work in production. Many times the reason for such issues is missing dependencies. Docker aims to solve this problem.
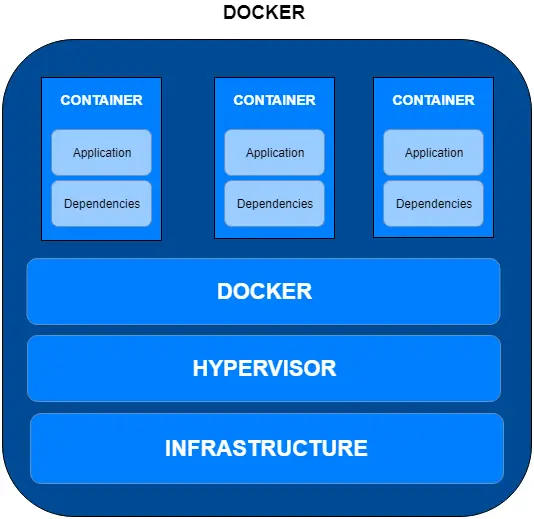
Docker’s popularity has surged over the course of this decade. More and more enterprises are embracing Docker for their production workloads.
There are lot of nuances to understanding Docker. You can refer to understanding the basics of docker for more information about Docker’s history, what makes it special and it’s high-level architecture.
Limitation of Docker
Despite the tremendous usefulness of Docker, it also has a limitation. While it is an extremely good choice for standalone applications, enterprise applications are often not so simple.
Enterprise Applications leveraging Docker would usually comprise of several microservices. Depending on the chosen data management pattern, these microservices would be speaking to each other. They can use an API-Driven communication pattern or the publish-subscribe model. Anyways, API, Microservices and Containers go very well together.
Whatever be the case, however, it is quite evident that more complex applications will inevitably span multiple containers. This can create challenges for developers. And that’s where the next topic of our post comes in.
Kubernetes to the Rescue
Kubernetes helps Docker become much more than what it really is.
A single container application does not need much effort to run and manage. However, when it comes to multi-container enterprise cloud applications, managing each and every container individually can lead to sleepless nights for developers.
That’s where Kubernetes comes to the rescue.
What does Kubernetes bring to the world of Containers?
You can consider Kubernetes as a container orchestration system.
But what does that even mean?
Kubernetes can co-ordinate across cluster of nodes at production level. One can install Docker on these separate nodes also known as Docker hosts. These hosts can be bare-metal servers or other virtual machines.
A collection of nodes that is managed by a single instance of Kubernetes is also referred as a Kubernetes cluster
Some of the bare minimum features Kubernetes provides are as follows:
- Running containers across multiple machines (physical or virtual).
- Scaling containers up or down based on changes in demand.
- Distribution of incoming load between various containers.
- Managing the storage shared by multiple instances of a container.
- Launching new instances of the container in case of failure.
In other words, while Docker enables you to create, run and manage a few containers, Kubernetes cranks up this ability many times over.
History of Kubernetes
Kubernetes has a pretty interesting history in itself and serves to show the rise of containerization in the world of microservices architecture.
In 2003-2004, Google started with the Borg system. It was a small-scale internal project at Google with the goal of providing a tool-set for cluster management. At its peak, the Borg system used to run thousands of jobs across thousands of applications within Google.
The same infrastructure was also used to deliver the initial version of Google Cloud platform. However, services like Google Compute Engine were often not suitable for projects where most of the resources were not used. This was not efficient. Plus, Docker had already came up on the scene.
What was missing from the puzzle was a great container management system. Sometime in 2014, Google introduced Kubernetes that was more or less an open-source version of Borg. The Kubernetes community grew rapidly and very soon companies like Microsoft, RedHat, IBM and Docker became part of this community.
However, one of the best decisions Google made was to make Kubernetes open-source. It was donated to Cloud Native Computing Foundation. This allowed it to gain a lot of traction within the community in a very short amount of time. Below graph shows the velocity of commits on the Kubernetes project over the years. It clearly shows the popularity of the project among developers.
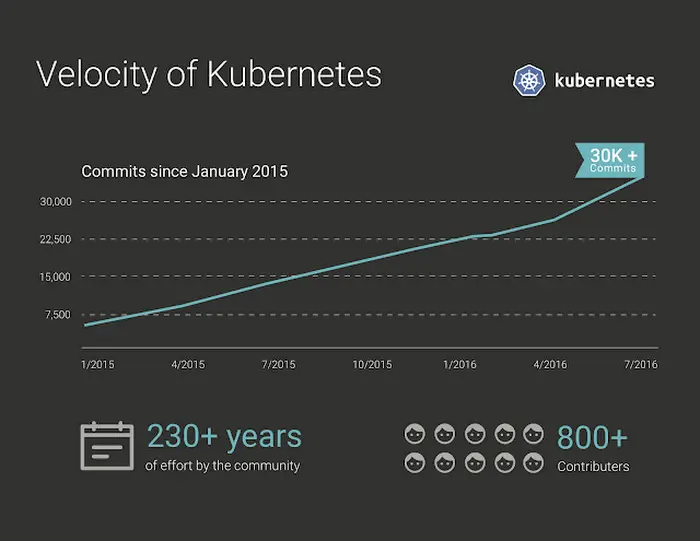
On March 6, 2018, Kubernetes Project reached ninth place in commits at GitHub
Quoted from Wikipedia https://en.wikipedia.org/wiki/Kubernetes
Thousands of organizations across the globe are now using Kubernetes. Because of going open-source, it has been developed by extremely talented engineers from across the industry. Needless to say, it has become the de-facto standard for managing Docker containers in the industry.
Kubernetes versus Docker Swarm
One would often find articles labeled Kubernetes versus Docker. Actually, this is misleading because as we have already seen, Kubernetes and Docker are not competitors. In fact, they supplement each other in providing the base infrastructure for building microservices application.
However, the competition could be between Kubernetes and Docker Swarm. If you don’t know, Docker Swarm is a Docker’s own native container management system. In Docker Swarm, containers are deployed as part of a swarm. An individual swarm can be interacted with as a unit.
The advantages of Docker Swarm lie in its tight integration with the Docker API. However, Swarm does not provide auto-scaling or external load balancing. Also, Swarm does not have a web-based interface like Kubernetes
At this point, Kubernetes enjoys a much larger popularity as compared to other container management systems. In fact, Docker has embraced Kubernetes despite having its own container management system. The desktop version of Docker (for Mac & Windows) comes with its own version of Kubernetes. This should remove any doubt as to what is the best choice if you are looking for a container management system in 2019.
Where does OpenShift fit in?
Now, we come to the real questions that often confuses people most.
How is Open Shift related to Kubernetes and Docker? Is there a Kubernetes vs OpenShift? Or are they mutually related?
To begin answering this question, let’s first understand what is OpenShift.
To put it succinctly, OpenShift is a product that you can install on your infrastructure. It can be used to run and manage your microservices. Moreover, it comes with paid support from Red Hat.
But still the question stands – how is OpenShift related to Kubernetes and Docker?
Here’s the answer. OpenShift internally uses Kubernetes and Docker. In other words, you can also think of OpenShift as a Kubernetes distribution managed by Red Hat.
Red Hat often labels OpenShift as a PaaS (Platform-as-a-service). Whether intentionally or unintentionally, it tries to not make the obvious association with Kubernetes. However, the fact remains that the foundation of OpenShift is Kubernetes and Docker.
That’s not to say that there isn’t a Kubernetes vs OpenShift situation out there. Often, the two platforms are compared with each other.
Also, there are obvious differences between the two:
- Kubernetes is an open-source project. If something bad happens to your installation, you can count on the community to support. However, In the case of OpenShift, you get paid support from Red Hat.
- Kubernetes and OpenShift both have a regular release cycle. But usually, Red Hat will be a bit behind in terms of the Kubernetes version being used.
- With OpenShift, you need to use Red Hat Enterprise Linux. However, if you just use Kubernetes, you can practically install it on any Linux distro such as Debian, Ubuntu or Fedora.
Kubernetes vs OpenShift – Who Wins?
OpenShift brings a lot of new features on top of Kubernetes. The below diagram shows some of the key features:
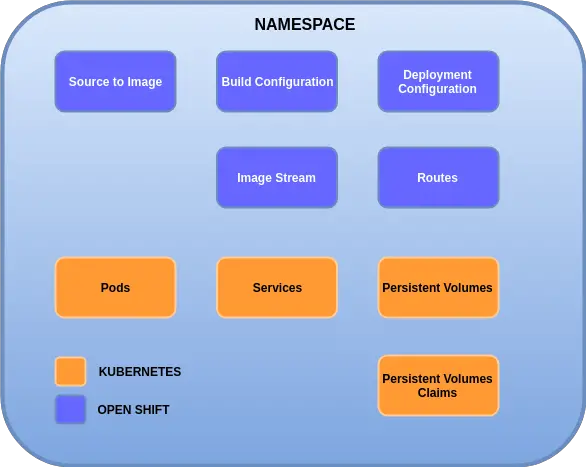
Project Areas – Right off the bat, OpenShift introduces the concept of project areas. A project area can be thought of as an augmented version of the Kubernetes namespace. Apart from the usual namespace features, the project areas also add permissions & roles aspect to the overall picture.
Source to Image – This is one of the most important features of OpenShift. As a product, OpenShift ships with a set of pre-built images. A developer simply has to provide the source code of the application which will be injected to the pre-built image and deployed.
Routes – This is another major addition in OpenShift. Route is an abstraction that sits over the Kubernetes services and allows access to an internal service from the outside world. This could be seen as an alternative to Kubernetes Ingress.
Build Configurations – This is basically a YAML configuration file that allow the developer to specify details about the source repository location, image parameters and so on.
Deployment Configurations – This set of configuration parameters impact the run-time environment of the application. For example, you could have JDBC URLs, connection credentials, other environment variables required by your application. You could also define deployment policies and number of instances that should be created.
Apart from these features, OpenShift also ships with builtin EFK stack. This can allow you to collect logs generated by the application. To top it all off, the web-console of OpenShift is much better to look at. Even though Kubernetes also has a web-console, the one that OpenShift has is miles better in terms of usability and functionality. If web-console is a really big factor for you, OpenShift definitely trumps the Kubernetes vs Openshift debate in that regard.
Conclusion
The hidden relation between Docker, Kubernetes and Open Shift is not so hidden after all. In fact, the relation is often symbiotic and thereby complements each other.
Just like Kubernetes solves many issues with Docker-only setup, Open Shift does the same for Kubernetes.
To recap, Kubernetes allows developers to manage multiple containers. It does most of the heavy-lifting with regards to container management such as scaling, load balancing, storage management and so on. Kubernetes has a wonderful community support. One can install it on almost all Linux distros.
OpenShift, on the other hand, provides a lot of good abstractions on top of Kubernetes. With OpenShift, your development teams can practically work without any knowledge of Docker and Kubernetes.
This might be a good thing or a bad thing depending on your perspective. If your organization is new to DevOps practices, OpenShift can help you ship code faster. At the same time you are able to leverage the power of Kubernetes and Docker indirectly. In this regard, OpenShift definitely wins the Kubernetes vs OpenShift debate.
However, since OpenShift takes an opinionated approach to the infrastructure, experienced DevOps teams may find themselves constricted. Kubernetes, on the other hand, provides a great amount of flexibility.
At the end of the day, it all depends on your situation and needs.

8 Comments
Robert · August 27, 2019 at 6:59 pm
Wonderful article. Cut through all the jargon to get to the point.
Saurabh Dashora · August 28, 2019 at 3:24 am
Hi Robert, Thanks for the wonderful feedback!
Anonymous · September 7, 2019 at 2:12 pm
Very nicely explained. Thank you.
Saurabh Dashora · September 8, 2019 at 3:19 am
Thanks for the feedback!
Anonymous · November 2, 2019 at 12:26 pm
Very nice article thank you!
Saurabh Dashora · November 4, 2019 at 11:43 am
Thanks for the feedback!
Anonymous · November 11, 2019 at 1:11 pm
really wonderful article.. finally the puzzle solved for me
Anonymous · May 18, 2020 at 7:35 am
Nice and simple explanation, Thanks.