Code reuse between multiple services is a hotly debated topic in software engineering.
You have some people fighting tooth and nail to prove that DRY (Don’t Repeat Yourself) is the way to go.
On the other end of the spectrum, the proponents of the “share nothing” philosophy are ready to engage in mortal combat to prove their point.
Between this battle are normal developers wondering how they should go about reusing code.
For starters, don’t bother to participate in any battle.
As a developer, your job is to build maintainable software and not engage in flame wars about software development patterns. Leave that to the so-called champions.
Having said that, code reuse is an integral part of a developer’s life and the question does come up quite frequently.
In this post, I will discuss 4 strategies for code reuse in software engineering that can help you build better applications.
Code Reuse Strategy#1 – Code Replication
In this strategy, shared code is copied into each service thereby avoiding code sharing completely.
Here’s what it looks like:
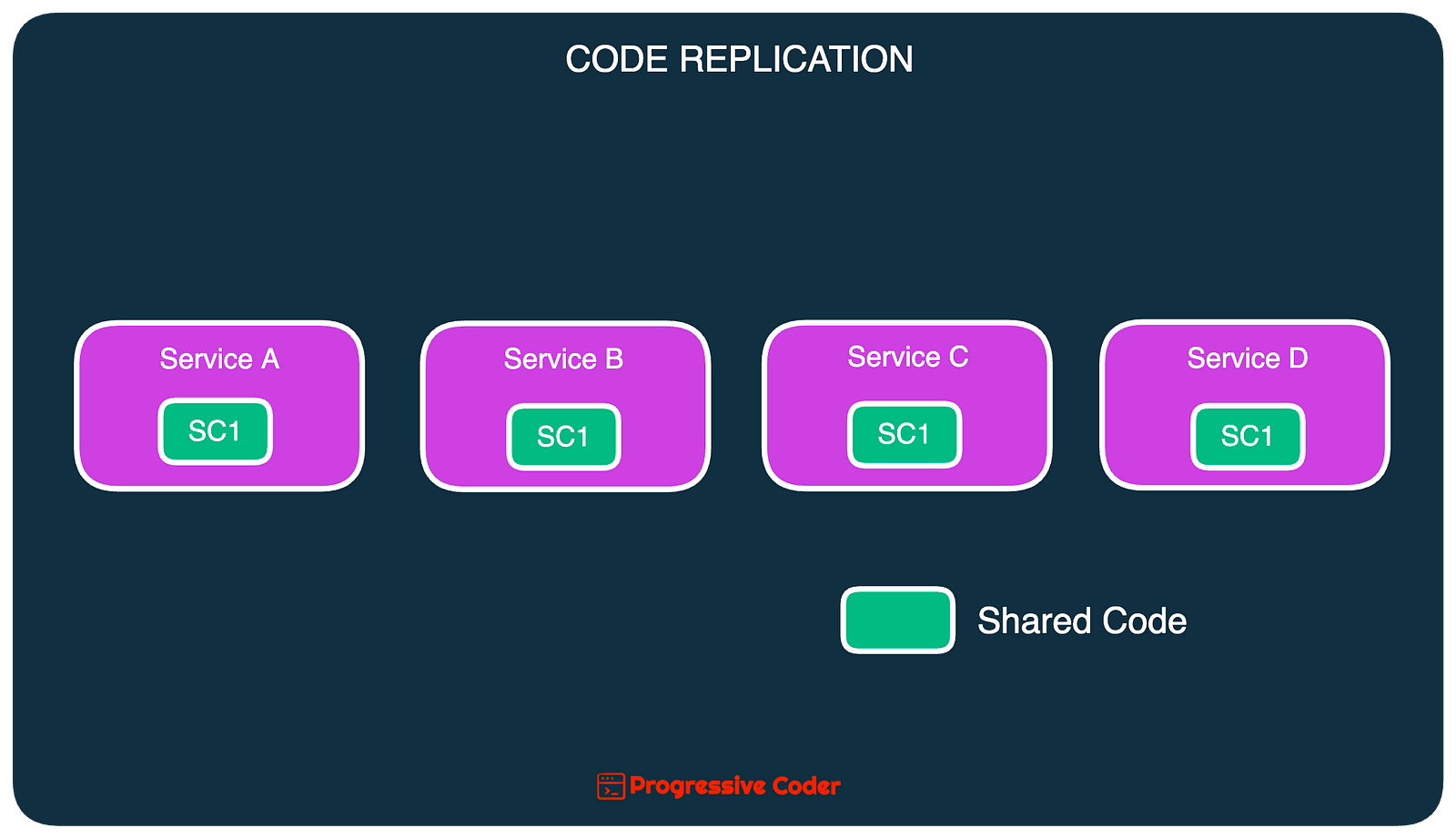
This technique was quite popular in the initial days of the microservices architecture.
As an advantage, this approach preserves the concept of a bounded context.
But it’s disadvantages outweigh the benefits.
Imagine finding a bug in the shared code. Or the need to make an important change to that code.
You will need to update all the services containing the replicated code. No matter how hard you try, there will be some level of code
Code Reuse Strategy#2 – Shared Library
Using a shared library is the most common technique for code reuse in software engineering.
A shared library is an external artifact. Think of a JAR file, DLL, or an NPM package containing the common source code. Multiple services can use the library to share the functionality.
Here’s an illustration that shows this particular arrangement.
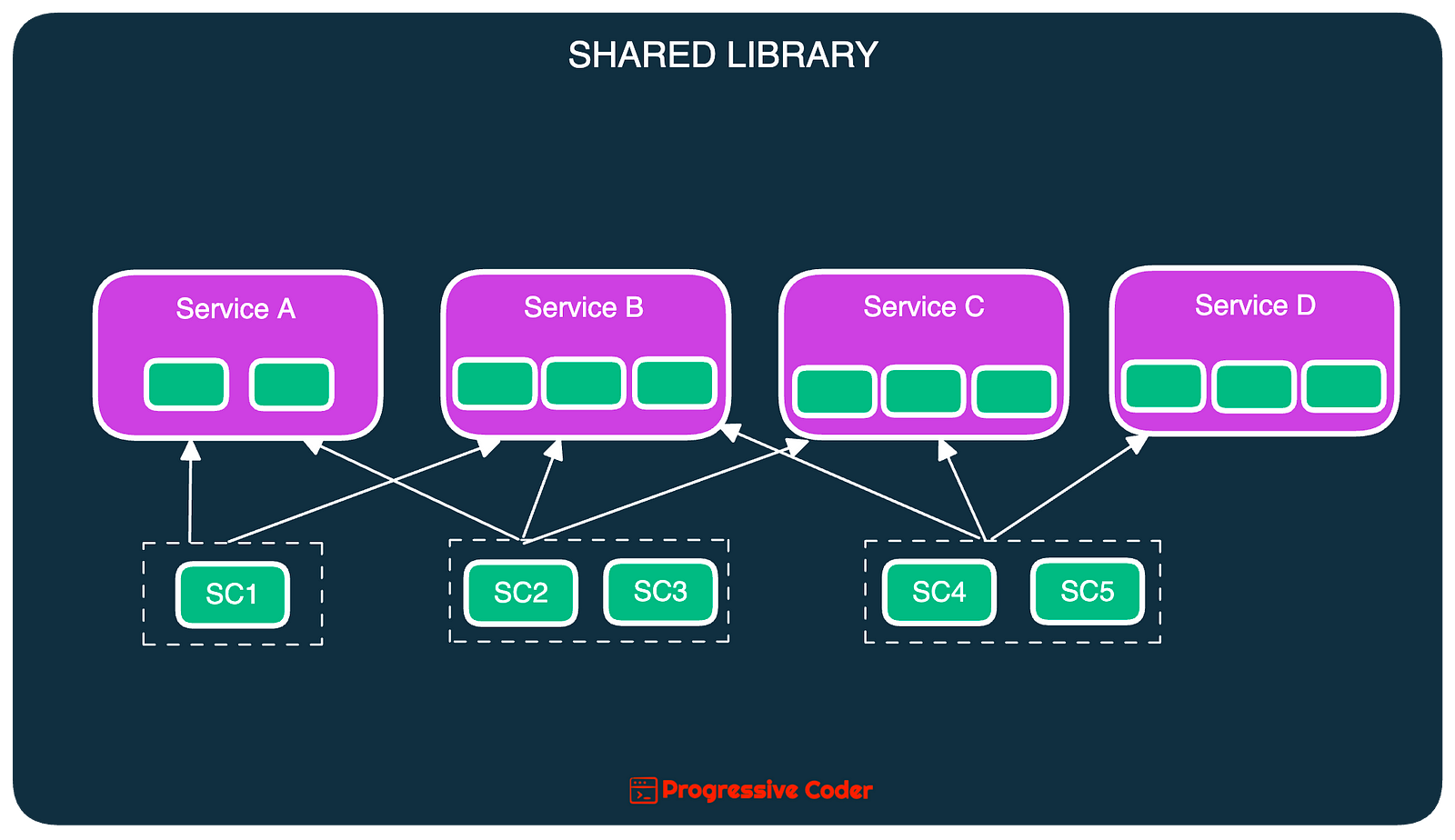
As you can see, a shared library may be used by one or more services.
The main advantage of this approach is that the shared library gets bound to the service at compile-time.
However, there are two main challenges that create trade-offs while sharing libraries:
- Dependency management
- Change control
If you have a big shared library with lots of functionality, dependency management becomes easier. Just include it in the service at build time and use the functionalities it provides.
But it creates a problem.
Any change to one of the classes in the shared library means every service has to adapt to the change even when it might not even be using the class.
This results in needless retesting and redeployment of all the services.
The other approach is to break up the big common library into small functionality-based shared libraries (such as logging, security, utility, etc.)
This approach reduces the impact footprint of a change but may result in a complex dependency matrix.
Code Reuse Strategy#3 – Shared Service
The main alternative to the shared library approach is the shared service approach.
In this strategy, you extract all the common functionality into a shared service.
Here’s what it looks like:
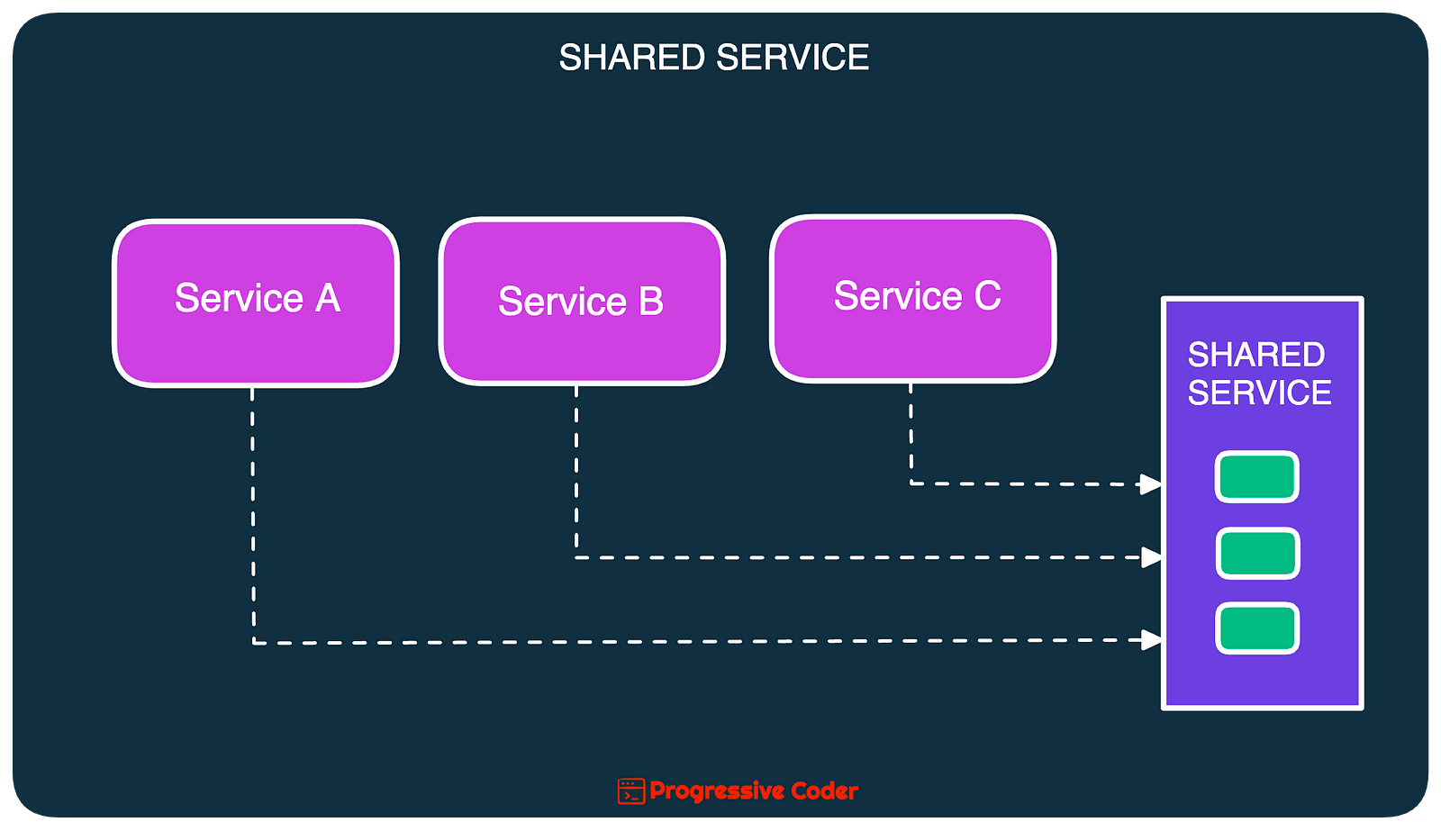
With this technique, you can avoid code reuse by placing the common functionality into a separate service with its own deployment path.
Of course, there are trade-offs with this approach as well.
Change Risk
Any faulty change to the shared service poses a risk of bringing down all the services that depend on it.
This is because the change to the shared service is a runtime change and not a compile-time change.
You can get around this issue by creating a new version of the service endpoint. But if the changes are frequent, you’d end up with a huge list of versioned endpoints.
Performance
The second trade-off is around performance.
In the shared service approach, every service must make an inter-service call to the shared service.
This means that the performance depends on the overall network latency.
Of course, the mitigation is to use gRPC to reduce network latency or go for asynchronous communication.
Scalability
The third trade-off is related to scalability.
The shared service must scale along with the services using the shared service. This can turn into a mess as multiple services concurrently access the shared service.
Code Reuse Strategy#4 – Sidecars
An application typically consists of two types of functionalities:
- Domain
- Operational
With domain functionalities, we want to go for loose coupling.
However, operational functionalities such as logging, monitoring, authentication, and circuit breakers do much better with a high-coupling implementation.
You don’t want each service team to reinvent the wheel for operational functionalities. Also, there is often a need for standardized solutions across the organization.
To reuse such operational functionalities across multiple services, you can leverage the Sidecar Pattern.
The Sidecar Pattern uses the same concept as the hexagonal architecture by decoupling the domain logic from the operational concerns.
Here’s an illustration that depicts the same.
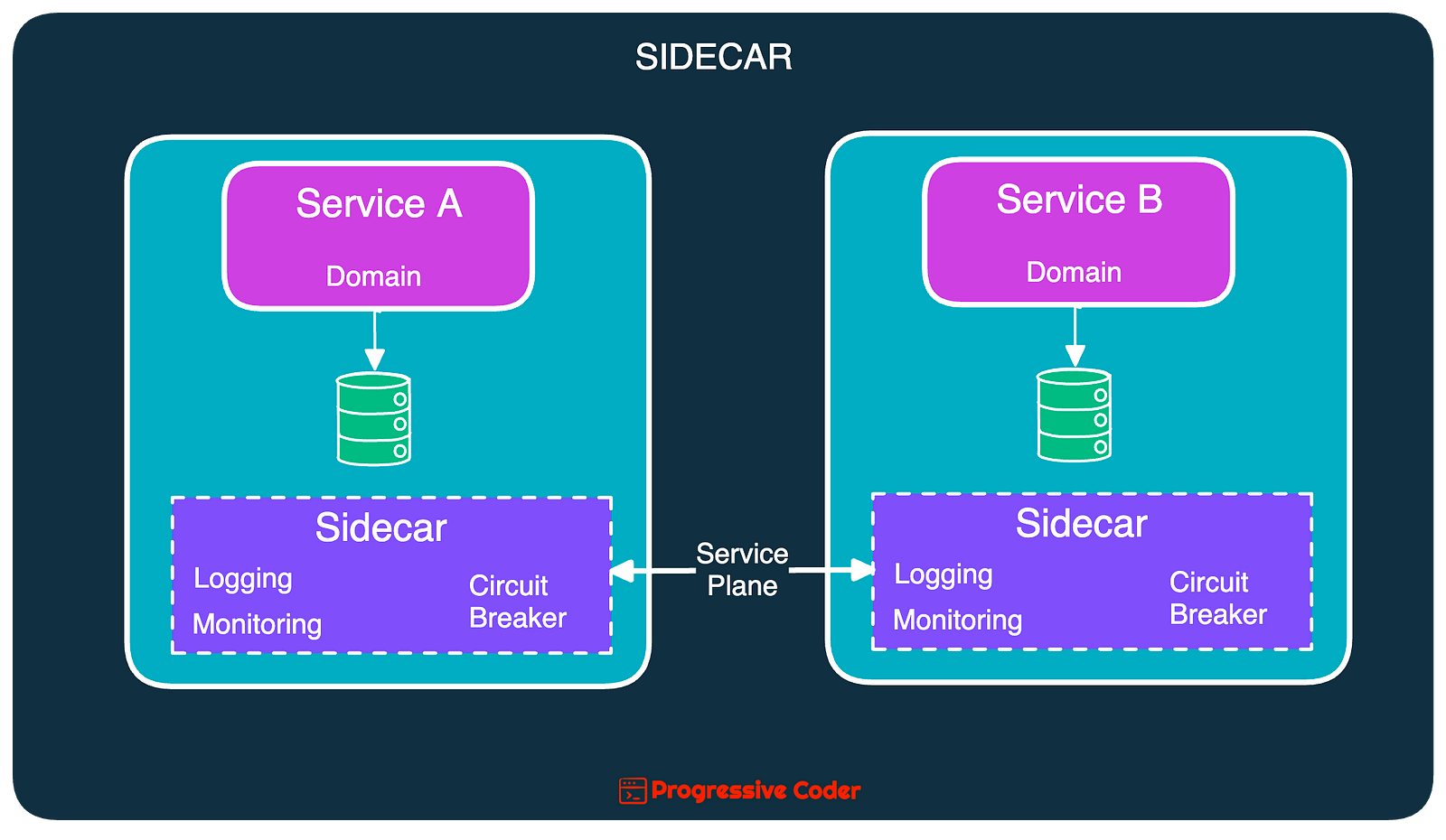
In this setup, every service includes the sidecar component that takes care of the operational functionalities.
All of this is managed using some sort of infrastructure piece such as Kubernetes or a service mesh.
Of course, it is important to ensure that we don’t end up reusing domain functionalities with the sidecar. Also, there is a risk that the sidecar component may grow too large or complex.
If interested, you can check out my post on how to implement a sidecar in Kubernetes.
Conclusion
Ultimately code reuse is an inevitable reality in software engineering when you want to share logic between multiple services.
Using the right approach for code reuse can go a long way in making the overall system more robust and maintainable.
Therefore, it’s good to put more thought into this at the beginning of the project development.
Which approach do you prefer and why?
Do share your views in the comments section below.
Also, if interested in more such challenges, check out my post on data ownership in a distributed system.

0 Comments