Distributed systems encourage you to break apart data and services. This means you’ve to think about data ownership in a distributed system more deeply as compared to a traditional system.
The common advice tends to proclaim that a service should own its data and that anyone wanting to access the data belonging to the service should access it via the service.
But things are not as straightforward in real life.
Consider this hypothetical scenario of a humble library management system.
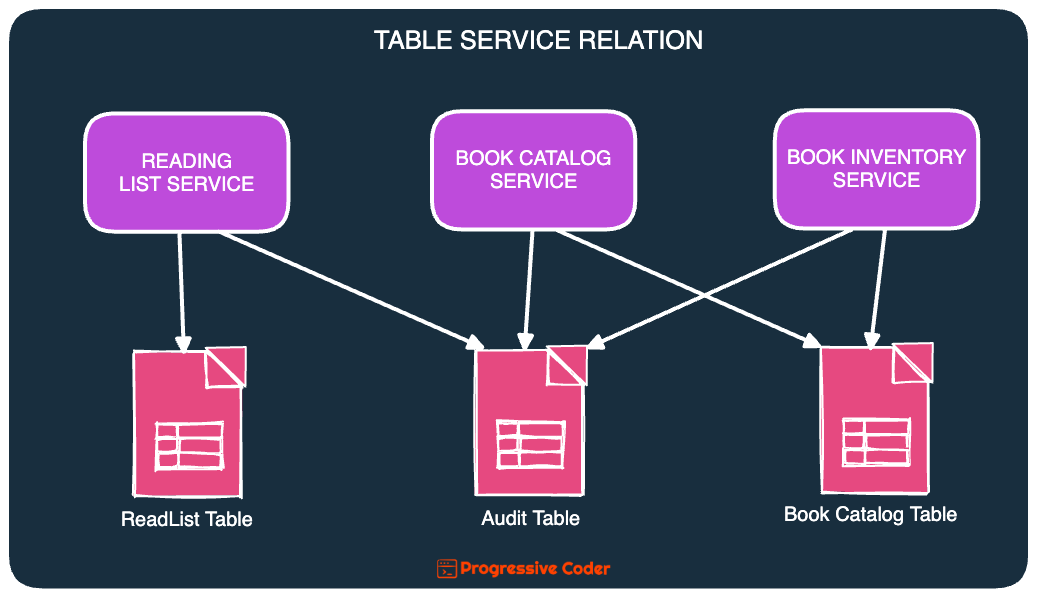
The system has 3 tables & 3 services:
- The ReadList table keeps track of a user’s reading list. The ReadingList service takes care of accessing the table.
- Next, there is a BookCatalog table. As the name suggests, it keeps track of all the books in the library. It also stores information about the inventory of the books. This table is accessed by the BookCatalog service and the BookInventory service.
- Lastly, there is the Audit table. It stores audit information on all the operations performed on the system. Due to its very nature, all services access this table to perform updates.
Even though you’ve potentially split your system into multiple services, the data layer is still largely shared with no clear ownership between a service and table.
Without clear data ownership, there are strong chances of issues due to the sharing of schemas and data between the services.
So, how do you establish clear data ownership in a distributed system?
There are 3 main types of data ownership approaches that you can leverage.
Let’s look at them one by one.
1 – Single Ownership
The first approach is the most straightforward. It’s known as Single Ownership.
In this approach, a table is owned by one and only one service. Anything that has to be done with that table will happen through the owner service of that table.
In the above example, the ReadList table is such a table. The ReadList service can be labeled a single owner of the table.
See the below illustration:
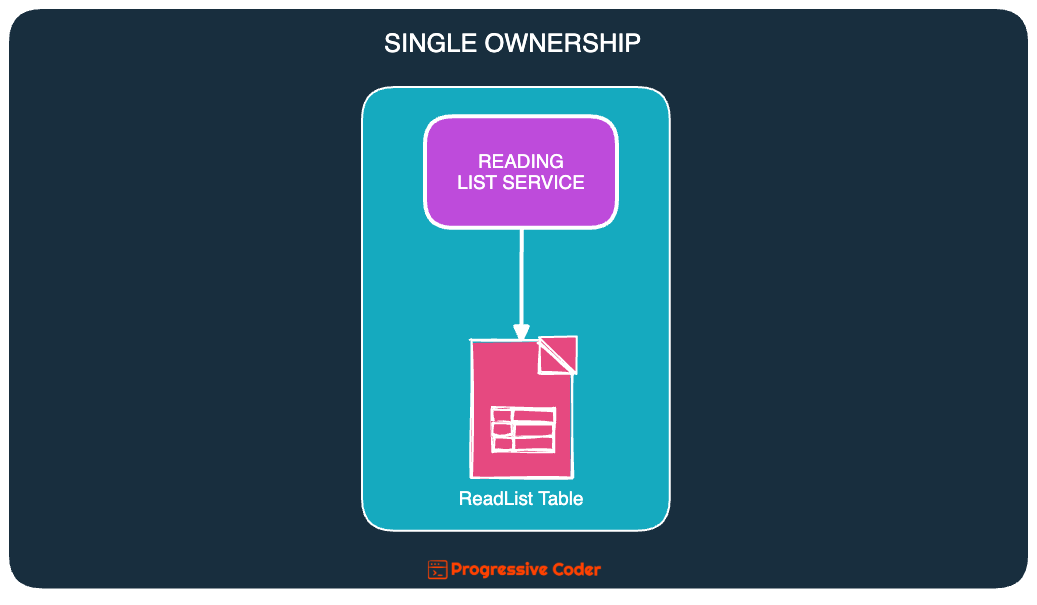
The ReadList table basically becomes part of the bounded context of the ReadingList service.
When trying to determine data ownership in a distributed system, it’s always a good idea to get the single ownership cases out of the way so that you can reduce the overall complexity of the system.
2 – Common Ownership
The next relatively easier data ownership case is when a particular table needs to be accessed by most of the services.
In our example case, the AuditTable is one such table.
However, since all services must write to the AuditTable, how to determine the owner?
Placing it in some sort of shared database seems like an easy solution but it introduces a bunch of data-sharing issues related to code reuse.
A more robust solution is to assign a dedicated service as the owner of such a table. Other services looking to perform write operations on this table would go through the dedicated service.
See the below illustration:
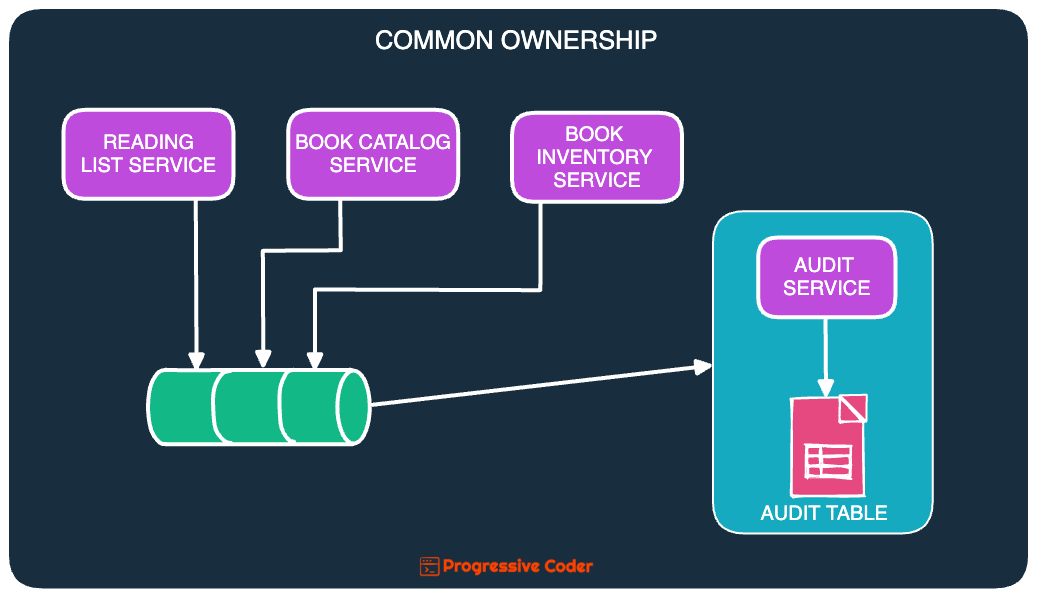
As you can see, we created a separate dedicated AuditService to perform write operations to the Audit table. No other service can directly write to the Audit table.
Also, if there’s no need for an acknowledgment that the data is written to the Audit table, the other services can use an asynchronous fire-and-forget approach using message queues.
3 – Joint Ownership
The third situation and the most complex one involves joint ownership of a table.
This situation occurs when multiple services can perform a write operation on the same table.
Mind you that it’s not the same as common ownership.
In the common ownership approach, all services had to access the same table. Here it’s mostly a matter of a couple of services.
See the below illustration:
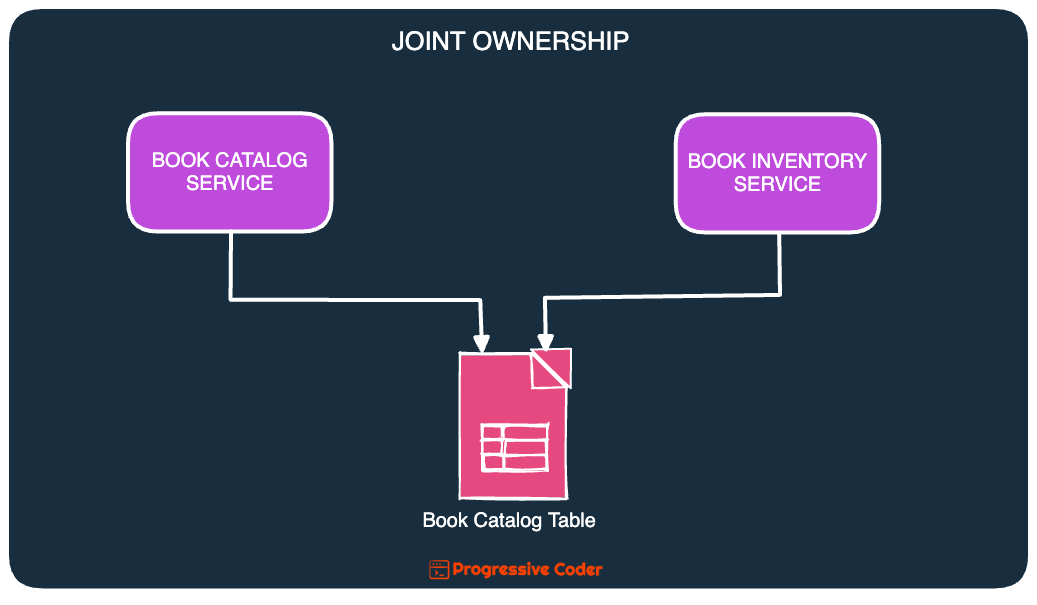
Both the BookCatalog service and the BookInventory service need to write data to the BookCatalog table.
The BookCatalog service writes the details about the various books. On the other hand, the BookInventory service updates the inventory status for each of the books in the library.
How do you manage data ownership in this scenario?
As a hint, you can use one of the below techniques:
- Table Split
- Delegation
- Service Consolidation
Check out the post on handling joint table ownership in microservices for a more detailed look.
Conclusion
Data Ownership is a big topic of discussion in a distributed system.
Since a distributed system consists of multiple services, we need to establish clear ownership rules between a service and it’s data.
The various ownership strategies discussed in this post provide us with key mental models to deal with this situation.
If you have any comments or queries about this post, please feel free to mention them in the comments section below.
0 Comments