We all know that duplicate messages are dangerous – in your application as well as your life.
Suppose you are the one who is responsible for making coffee for everyone in your family. As per the house rules, if someone wants to have coffee, they need to write it down on a piece of paper ???? placed on the kitchen stand.
Let’s say your son wanted to play a childish game and wrote “1 COFFEE PLEASE” twice. You end up with the below messages.
“1 COFFEE PLEASE”
“I NEED A COFFEE”
“1 COFFEE PLEASE”
You see these messages written on the paper and start processing them one by one.
When you come to the 2nd message written by your son, you have no way of knowing whether it was a real demand or just a joke.
What do you do?
You make an additional coffee that’s not really needed, wasting resources and time in the process.
Basically, you become part of your son’s joke and are none the wiser.
The same thing can happen in your application as well.
Due to various system issues or even business scenarios, your application service might receive duplicate messages and if you don’t handle them properly, you might run into some serious issues.
For example, serious things like applying the same bank transaction twice.
Duplicate messages can ruin the health of your system. It’s important to track duplicate messages and deal with them according to your business scenario.
However, to fight an enemy, you must know the why of the enemy. Knowing the why gives you better workarounds, better solutions, and so on.
1 – The 3 Message Delivery Guarantees
To start understanding things better, let’s look at the three 3 possible message delivery guarantees:
- At-Most-Once: Message not delivered more than once. But may not be delivered at all.
- At-Least-Once: Message delivered at least once. But can be delivered a thousand times as well.
- Exactly-Once: Message delivered once and only once.
Exactly-Once sounds beautiful. It is the ideal situation.
If messages are delivered only once, there’s no need to worry about duplicates.
But Exactly-Once is not a real possibility. We actually fake it using different approaches like idempotency and deduplication.
Idempotency
An idempotent operation is an operation that can be repeated multiple times without changing the result.
For example, things like updating customer addresses or contact details are naturally idempotent operations. No matter how many times you execute the operation, the result is always the same.
If you are able to create an idempotent operation to process your events, you are essentially implementing Exactly-Once semantics for any downstream functionalities.
But life is not so simple.
Not all operations are naturally idempotent. Examples:
- You cannot apply the same withdrawal transaction on a bank account multiple times without actually withdrawing the money as many times.
- Similarly, you cannot place the same order multiple times without actually placing the order as many times.
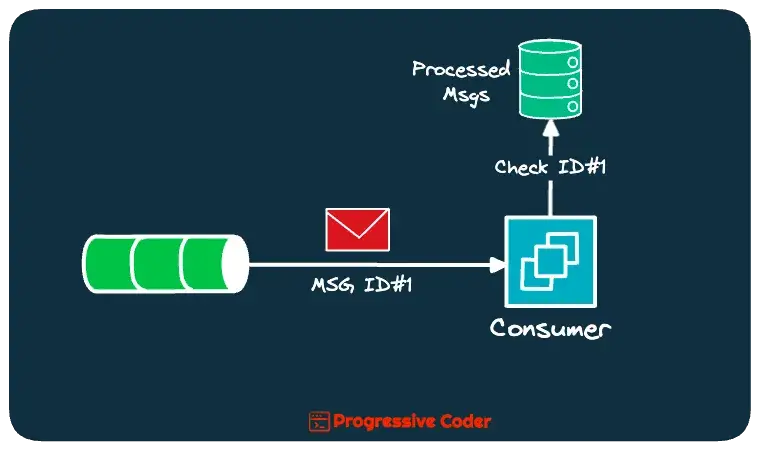
Check the below illustration:
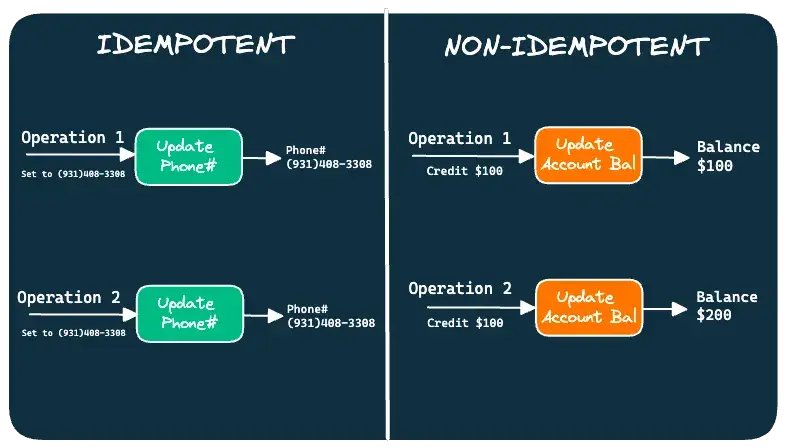
The point is that non-idempotent operations require a mechanism to check whether the messages they are receiving are duplicates or not.
De-duplication
De-duplication is a technique that helps deal with duplicate messages in a non-idempotent operation.
The easiest way to perform de-duplication is to have some sort of identifier for every message.
Whenever a new message comes along, you check if the message identifier is already processed. If yes, it is a duplicate and you discard it.
In the coffee situation from earlier, you can have each family member write their name next to the message asking for coffee.
“1 COFFEE PLEASE” – John
“I NEED A COFFEE” – Alice
“1 COFFEE PLEASE” – John
This way you can immediately spot that your son is probably playing a prank and you can ignore the request or call him out.
In essence, I like to view de-duplication as a sort of black box that takes in duplicate messages and spits out unique messages. How it accomplishes the task depends on the requirement.
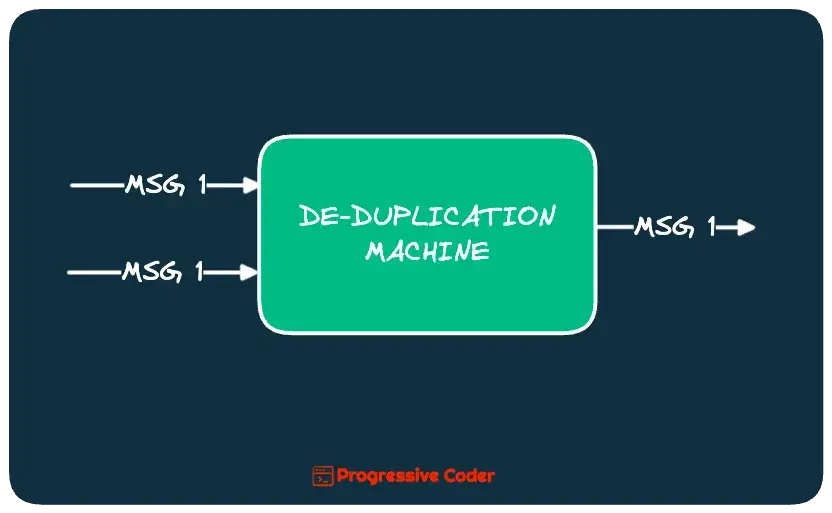
Of course, de-duplication has its own set of problems.
You need to maintain a continuously growing storage to keep track of duplicate messages and their identifiers.
If the consumer service that is processing the messages has multiple instances, then you also introduce a single point of failure (storage) that can bring the whole system down.
Either way, you are still dealing with At-Least-Once delivery guarantees and wrapping it within a nice package. Basically, you are allowing duplicate messages to occur, but stopping them from creating issues for your application.
2 – Why At-Least-Once Leads to Duplicate Messages?
No one wants to intentionally create duplicate messages. It happens accidentally.
Here are a couple of examples.
Consumer Acknowledgments
A message broker delivers a message to the consumer service. The expectation is that the service acknowledges once it receives the message.
Here’s what it looks like in practice:
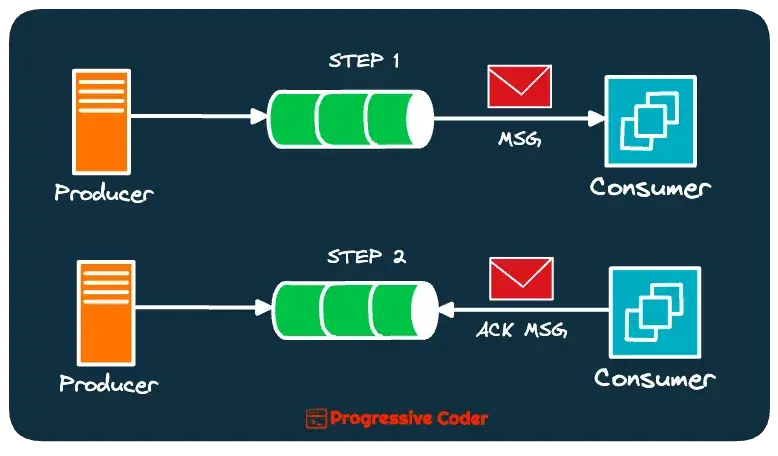
But the service may not be able to acknowledge the message for multiple reasons:
- The consumer might fail (for whatever reason) before sending the acknowledgment to the broker. In this case, the broker will send the message again to the consumer.
- Generally, brokers have a timeout before which they should receive the acknowledgment. If the consumer service is slow and sends the acknowledgment after the timeout expires, the broker will end up re-sending the message to the consumer.
- The consumer might be sending an acknowledgment using some specific piece of code that is conditionally executed. If that piece of code does not run, the broker will think the message wasn’t delivered and it will re-send the message to the consumer.
In the At-Least-Once message delivery guarantee, the broker will continue to resend the message till the point it does not receive an acknowledgment.
Producer Sending Duplicate Messages
A message producer can also send duplicate messages.
For example, consider a scenario where a producer pulls messages from the database and publishes them to a broker. After publishing, it marks the message as published in the database.
Since these are two different operations, the database update can fail after the message has been published.
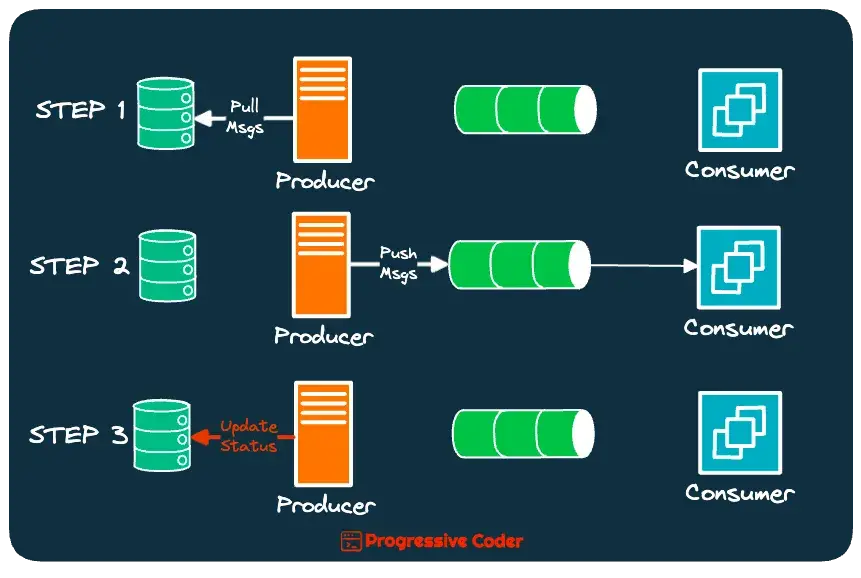
However, At-Least-Once guarantees that the message must be sent until it is definitely published. Therefore, the producer ends up publishing the same message again.
3- Keeping Track of Duplicate Messages
At-Least-Once is good. It makes sure that we don’t actually lose any messages.
The only thing we have to do is track duplicate messages and take appropriate action based on our requirements.
There are multiple ways you can track duplicate messages.
Identifying Message Uniqueness
The first step is to have some sort of mechanism to identify whether a message is unique.
There are several options to do so:
Unique Identifier
Tag every message with a unique id (like a UUID).
UUIDs are basically identifiers that we can use to uniquely identify information in a distributed computing environment. For example, 550e8400-e29b-41d4-a716-446655440000 is a UUID.
If your service receives two messages with the same id, you can conclude that these are duplicate messages.
Increasing Sequence Number
Use an ever-increasing sequence number for each new message.
If the service receives a message that has a sequence number less than the last sequence number processed, you treat it as a duplicate.
Hashing the Content
Hash the content of the message and store it.
For every new message, hash and compare it with the previously stored hashes. If you find a match, you can conclude that the message is a duplicate.
Use a Cache or a Database
Once you finalize the mechanism to identify the uniqueness of a message, you need a way to actually store the information.
Usually, there are two main approaches:
Shared Database
A shared database is one of the simplest options to store message IDs or other deduplication information.
This approach works pretty well even when one service runs on multiple instances.
All the instances of the service get access to the same database so that they can handle duplicate messages.
Of course, setting up a database is not a trivial matter.
I would recommend the shared database approach only if you have to store information about a large number of messages for an extended period of time. If it’s something that is already a part of your domain, that’s even better.
Think of things like bank transaction information or customer orders on an e-commerce platform.
???? Cache
The second option is to use a cache to store message IDs or other deduplication information such as the hash of the content.
You can use caching solutions such as Redis or Memcached or just plain old in-memory caching.
I recommend going for a cache when you have to store a small number of messages for a relatively smaller duration.
Windowing Technique
Another useful technique to handle deduplication is windowing.
In this technique, you keep track of messages processed only within a certain time window.
Duplicates are discarded only if they arrive within the same time window. Else, they are processed like a new message.
Check the below illustration:
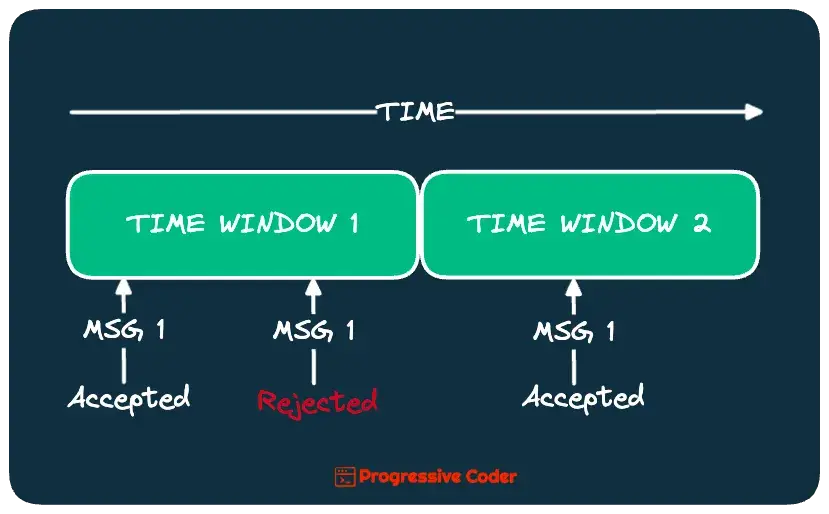
For example, on a social media platform, you might discard duplicate messages by a particular user for a specific time window so as to prevent spammy content.
4 – Exactly-Once Isn’t Exactly Impossible
Okay, I did mention earlier that Exactly-Once isn’t possible.
This is not actually true.
Powerful messaging systems like Kafka have started to provide Exactly-Once delivery guarantees.
Kafka Idempotent Producer
As we saw earlier, idempotency helps us take care of duplicate messages.
Keep implementing idempotent operations and you need not worry about duplicate messages. But not all business processes are idempotent.
What if the broker itself made things idempotent for the consumer?
That’s what happens in the case of Kafka’s Idempotent Producer.
With this feature, Kafka ensures that messages produced on a topic are unique and that duplicates are automatically discarded.
All you have to do is set the idempotent.producer flag to true and acks property to ‘all’ while configuring a Kafka Producer.
Here’s an example of a Kafka Producer configuration in Java.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("enable.idempotence", "true");
The producer sends each message with a unique sequence number and the broker tracks the sequence number for each producer. The acks value of ‘all’ ensures that all in-sync replicas of the partition have received the message.
If a producer sends a message with a sequence number that has already been seen, the broker discards the message as a duplicate. This way, the consumer is always guaranteed to receive unique messages.
Kafka Transactional API
Another way Kafka supports Exactly-Once is through the use of Transactional API.
The API guarantees that either all messages produced within a transaction are successfully committed or none of them are.
It works both on the producer and consumer side.
- A producer can ensure that a message is either successfully delivered and processed Exactly-Once or not delivered at all.
- Also, a consumer can ensure that it only processes messages that have been successfully committed within a transaction.
No matter how hard you try, duplicate messages can still exist like weeds.
I would rather deal with duplicate messages than missing messages.
Going for Exactly Once can also have performance implications unless it is natively supported by platforms such as Kafka.
When tracking duplicate messages, I believe combining methods based on your business scenario can give better results.
Over to you
- Which delivery guarantee do you prefer the most?
- In case of duplicate messages, do you keep track of them?
- If yes, what do you do once you confirm that a message is duplicate?
Leave your replies or thoughts in the comments section.
And that’s all for this post.
If you found this post useful, give it a like and consider sharing it with friends and colleagues.
Looking for More?
Are you struggling to grow in your current role and stay relevant in your organization?
Do you feel you are getting short-changed when it comes to promotions?
You might think that hard work is the answer.
And of course, hard work is important. But you also need a clear direction.
At Progressive Coder, my goal is to provide actionable information that can help you sharpen your skillset technically as well as non-technically so that you can become the best at your job and get the recognition you deserve.
Subscribe now and get two emails per week (packed with important info) delivered right to your mailbox.

0 Comments