Whatever be our use-case for Kafka, we will always have a Producer that writes data to Kafka and a Consumer that reads data from Kafka. In this post, we will uncover the mysteries of Kafka Producer with examples.
- How Kafka Producer works under the hood?
- How to create a Kafka Producer and send records to Kafka?
- Should you use fire-and-forget, synchronous send or asynchronous send for sending messages?
If you are new to Kafka, check out our detailed Kafka Introduction.
1 – Behind the scenes of Kafka Producer
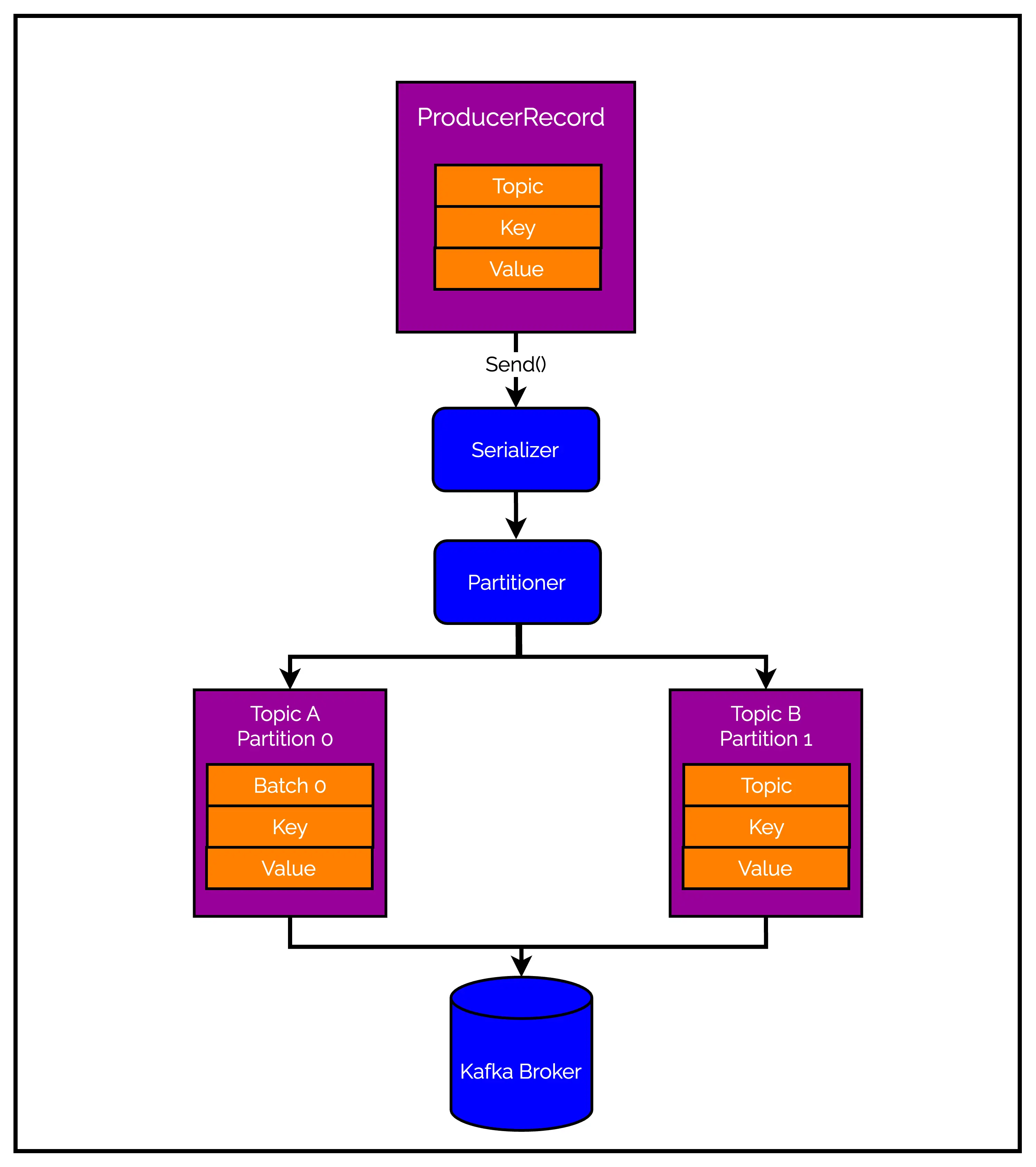
The first step in producing messages to Kafka is by creating a ProducerRecord . The ProducerRecord should contain two mandatory items:
- The name of the Kafka Topic where we want to send the message
- The message that we want to send
Optionally, we can also specify a key, a partition, timestamp and a collection of headers.
So, what happens after we send the ProducerRecord? Well, a number of things take place before our record even reaches Kafka.
- The first thing the Producer does is serializing the key and value objects to byte arrays. This is done so that the data can be sent over the network.
- If we didn’t explicitly specify a partition, the data is sent to a partitioner. The partitioner will choose a partition for us. This is usually done based on the ProducerRecord’s key (if we have specified one).
- Once a partition is selected, the Producer knows the topic and the partition the record will eventually go to. However, it does not immediately send out the record. The record is added to a batch of records that will also be sent to the same topic and partition. A separate thread is responsible for sending the batch to the appropriate Kafka brokers.
- Ultimately, at some point of time, the record makes its way to the broker.
When the broker receives the messages, it sends back a response to the Producer. If the messages were successfully written to Kafka, the broker will return a RecordMetadata object. This object contains information such as the topic, partition and the offset of the record within the partition.
INFO
The offset is an integer value that continually increases as more messages are added to the Kafka broker. Basically, it is a piece of metadata that Kafka adds to each message as it is produced. Each message in a given partition has a unique offset and the next message has a greater offset than the one before it. By storing the next possible offset for each partition (in Kafka itself), a consumer can stop and restart message processing without losing track.
The broker, however, can also fail to write the message. In such a case, it will return an error. When the Producer receives an error, it may retry sending the message a few more time before giving up and returning an error to the application.
All of this may sound like a lot and therefore, you can check out the below illustration to make things clear.
2 – Creating a Kafka Producer
Time to start with some actual code.
The first step to write a message to Kafka is creating a producer object. There are three mandatory properties that are need while creating the producer object.
bootstrap.servers– This is a list ofhost:portpairs of brokers that the producer can use to create the initial connection to Kafka. It is good to provide at least two brokers. If one goes down, the producer can still connect to the cluster.key.serializer– This is the name of the class that will be used to serialize the keys of the records. Though Kafka brokers expect byte arrays as keys. However, the producer interface allows us to use parameterized types. So, we can use any valid Java object as a key. The producer will use this class to serialize the key object to a byte array.value.serializer– As evident, this is the name of a class that will be used to serialize the values of the records. Basically, this is the same askey.serializerexcept it is applicable to the value part of the record.
Below is how we can create a Producer object.
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", StringSerializer.class);
kafkaProps.put("value.serializer", StringSerializer.class);
KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);We first create a Properties object and add the three mandatory properties – bootstrap.servers, key.serializer and value.serializer . In this example, we assigned a special class StringSerializer for both the key and value. This class is provided as part of the Kafka client.
Important Points about the Kafka Producer
- The
key.serializerandvalue.serializershould be set to the name of a class that implements theorg.apache.kafka.common.serialization.Serializerinterface. - We may not be interested in setting a key for our record. However, we still need to set the value for the
key.serializer. In such a case, we can use the specialVoidSerializer. - Our Kafka cluster might have several brokers. However, we don’t need to include the entire list as part of the
bootstrap.servers. Just one or two are enough. The producer will get more information about the other brokers after the initial connection to the cluster. - Most of the control over producer’s behaviour is done by using the appropriate configuration options. There are many more configuration options that we will discuss in a later section. The three discussed here are the mandatory ones without which we cannot proceed.
3 – Sending Messages using Kafka Producer
Once we have configured our Producer, we can now use it to actually send messages to the Kafka broker. As mentioned in the beginning, there are three main methods of sending messages:
- Fire and Forget
- Synchronous Send
- Asynchronous Send
We will look at each case one-by-one. However, before that, we need to add the below dependency in the pom.xml file in case we are using Java Maven project.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>This dependency pulls in the official Kafka client package that contains all the classes we are using to create and use a Kafka Producer.
3.1 – Fire and Forget Approach
In this approach, we send a message to the Kafka broker and forget about it. Basically, we don’t care if it arrives successfully or not.
Since Kafka is highly available, chances are that it will arrive successfully. Also, in case of any issue, the Producer will retry sending the messages automatically.
However, if there is an error that cannot be retried or there is a timeout, messages will get lost. The application will not get any information or exceptions about this.
Below is an example of the fire and forget approach in our Java Maven project.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaDemo {
public static void main(String[] args) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", StringSerializer.class);
kafkaProps.put("value.serializer", StringSerializer.class);
KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);
ProducerRecord<String, String> record = new ProducerRecord<>("topic-1", "msg", "kafka trial message");
try {
producer.send(record);
} catch(Exception e) {
e.printStackTrace();
}
producer.flush();
}
}The first segment of the code deals with configuring the KafkaProducer instance.
Once the instance is configured, we create a ProducerRecord object. The constructor of this class takes a few input parameters:
- The name of the topic (in this case
topic-1) - The key of the message
- Lastly, the actual message value
Next, we send the message to the Kafka broker using the producer.send() method. The call to this method is wrapped within a try-catch block to handle exceptions that might arise.
At the very end, we flush the producer by calling the flush() method. If you recall, Kafka Producer does not actually send the message immediately but places it in a batch. A separate thread ships the message after some time. However, the above application terminates after calling producer.send() even before a separate thread can send the message. The flush() method basically flushes the accumulated records in the producer with immediate effect.
3.2 – Synchronous Send Approach
On a purely technical level, Kafka Producer is always asynchronous. However, we can force it to behave in a synchronous manner.
Check out the below code:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaDemo {
public static void main(String[] args) {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", StringSerializer.class);
kafkaProps.put("value.serializer", StringSerializer.class);
KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);
ProducerRecord<String, String> record = new ProducerRecord<>("topic-1", "msg", "new producer");
try {
producer.send(record).get();
} catch(Exception e) {
e.printStackTrace();
}
}
}
What’s the difference here?
Nothing much! We have turned the send method to a synchronous operation by using producer.send(record).get().
Basically, the send() method returns a Future object. Using the get() method, we wait on the Future object to make sure if the call to send() was successful or not. The method will throw an exception if the record is not sent successfully to Kafka. If there were no errors, we get a RecordMetadata object that contains information such as the offset of the message.
INFO
Notice that here we don’t use flush(). There is no need for flushing the producer. The producer will move forward only after receiving the response from Kafka.
You must have already noticed the issue with this approach. With synchronous send, we are essentially making a trade-off on performance. Brokers in a typical Kafka cluster may take some time to respond to produce requests. With synchronous messages, the sending thread of our application will spend this time waiting and doing nothing else. This can dramatically reduce the performance of our application.
3.3 – Asynchronous Send Approach
This is the third approach for sending messages to Kafka and is arguably the best approach.
Basically, here we call the send() method of the Producer with a callback function. The callback function gets triggered when it receives a response from the Kafka broker.
Check out the below code:
package com.progressivecoder.kafkaexample;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.Properties;
@SpringBootApplication
public class KafkaExampleApplication implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(KafkaExampleApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "localhost:9092");
kafkaProps.put("key.serializer", StringSerializer.class);
kafkaProps.put("value.serializer", StringSerializer.class);
KafkaProducer producer = new KafkaProducer<String, String>(kafkaProps);
ProducerRecord<String, String> record = new ProducerRecord<>("topic-1", "msg", "new kafka async");
try {
producer.send(record, new DemoProducerCallback());
} catch(Exception e) {
e.printStackTrace();
}
}
}
class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
e.printStackTrace();
}
}
}
Here, we are using a slightly different setup – A Java Spring Boot application. With Spring Boot, our application will continue running even after we send the message to Kafka. This way we can easily configure the callback. If you are new to Spring Boot, check out this post on getting started with Spring Boot.
- To use callbacks, we need to declare a class that implements the
Callbackinterface provided by theorg.apache.kafka.clients.producerpackage. This interface has a single functiononCompletion(). - If there is an error from Kafka, the
onCompletion()will have a non-null exception. We can handle the same by printing the stack trace. - In case of success, we get the
RecordMetadatathat contains the topic, partition and offset of the message. - Once the class is defined, we pass an object of this class while calling the
producer.send()method. The entireKafkaProducerconfiguration setup and sending the message is within therun()method that comes from theCommandLineRunnerinterface provided by Spring Boot.
The real advantage of callback approach is when we fail to send message. With the callback in place, we can take some action in case of message failure such as throwing an exception, logging an error or writing the failed message to some other place for analysis.
INFO
The callback functions execute in the producer’s main thread. We should make sure that the callback is reasonably fast and there are no blocking operations within the callback as it can slow down the producer.
Conclusion
With this, we have successfully looked at Kafka Producer example with the three different approaches – fire and forget, synchronous and asynchronous send.
While any approach is fine, we tend to prefer the async send approach in production as it allows us to send messages at high performance while also managing error situations and exceptions if any.
Want to learn more about Kafka message producing? Check out this post on implementing your own Kafka Custom Partitioner.
Please do share your views on the matter in the comments section below. And also, if you are looking for more such posts, please do subscribe to the newsletter and you can also follow me on Twitter.
In case of any queries or comments, please feel free to mention them in the comments section below.
0 Comments