Over the years, Kafka has become super popular among developers and large organizations. What began as an internal project at LinkedIn has turned into one of the most significant components of event-driven systems. It is used in some of the largest data pipelines in the world and organizations such as Netflix and Uber are extensively relying on Kafka. In this post, we will aim for a detailed Kafka introduction.
But what is the reason for this tremendous growth in Kafka’s adoption?
The reason is Kafka’s ability to reliably manage the flow of data in your application at a very large scale.
As we all know, data is extremely important for any business out there. In today’s world, data powers every enterprise!
And Kafka happens to be the conduit through which this power runs.
With this Kafka introduction, we will understand three important aspects about Kafka:
- Basic components of Kafka
- Why we need Kafka?
- Common use-cases of Kafka
Basically, this Kafka introduction post will be our foundation for going deeper into Kafka in the coming sections. Earlier we had a post on Kafka installation. You can check it out in case you are interested in installing it on your system.
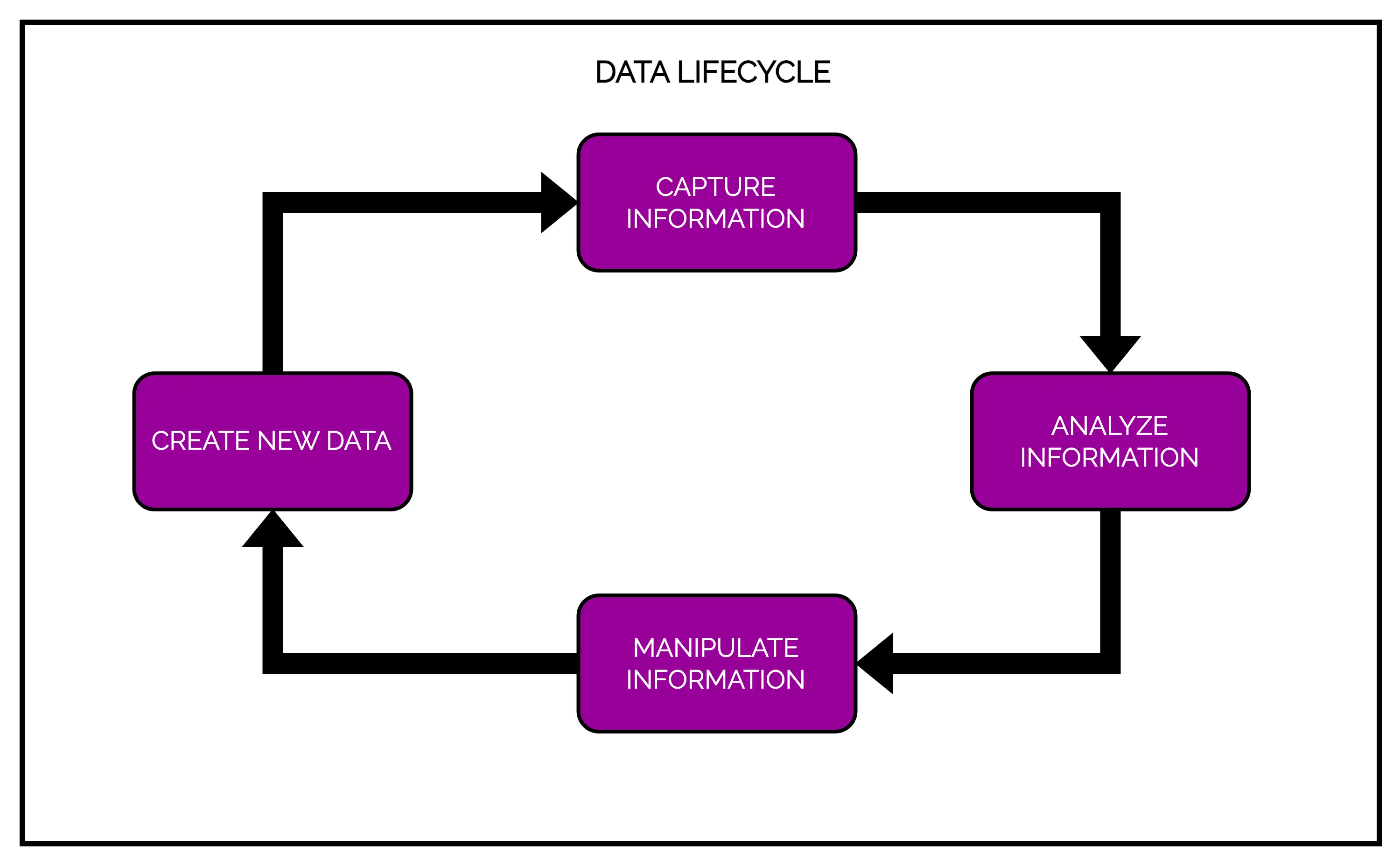
1 – The Lifecycle of Data
Any software system has a data lifecycle that usually works as below:
- Take information in
- Analyze the information
- Manipulate the information
- Create more data as output
Typically, applications create various types of data such as log messages, metrics, user activity and outgoing messages. Every byte of data is important and the goal of any good application is to reliably get the data from the point of creation to the point of analysis.
For example, in a website like Amazon, data is created whenever the user clicks an item of interest on the shopping page. The information is sent to the recommendation engine that analyzes the user’s activity to determine the appropriate recommendations for the user.
Though the data was created on the website (when the user clicked some product link), it became useful for business growth only after it reached the recommendation engine for analysis. Faster the data movement, the more agile or responsive our organizations can become. Less cumbersome the movement of data, more focus can be given to the core business logic.
To facilitate this data movement, we typically use data pipelines. In a data-driven enterprise, the data pipeline is one of the most critical components. And Kafka happens to be the data pipeline.
2 – Publish/Subscribe Messaging
Before jumping into the specifics of Apache Kafka introduction, we need to understand the concept of publish/subscribe messaging system.
Publish/subscribe is a messaging pattern in which a sender or a publisher of data does not target a particular receiver. The publisher simply classifies the data or message before sending. For example, the publisher might say that a given message belongs to the metrics category. The receiver’s job is to subscribe to a particular category in order to receive data of that type.
To facilitate the interaction between publisher and subscriber in such systems, we need a central authority known as the broker.
When compared to the real-world, this setup isn’t so different from subscribing to a magazine or a newsletter. A publisher publishes the newsletter and the subscribers who have registered for it receive the newsletter in their mailbox.
If your application is data-driven, chances are that it may have a need for publish/subscribe messaging pattern.
But why do software systems end up needing something like the pub/sub style of interaction?
Typical use cases for publish and subscribe start out when one system needs to communicate with another system but the normal request response approach creates a bottleneck.
For example, IT operations team might want to build a dashboard displaying application metrics for a particular frontend application. Usually, we open a direct connection from the frontend application to the dashboard application. Metrics data is pushed over this connection and are displayed by the dashboard application.
Over time, more requirements emerge such as the need to analyze metrics over a longer term.
Clearly, this won’t work well with the typical dashboard approach. To actually perform metrics analysis, we need to receive and store the metrics before we can analyze them over a period of time. To accomplish this, we end up creating a new service.
At this point, it’s not hard to imagine that more applications may start sending metrics and the number of connections to the metrics collection service rise dramatically. This is clearly not an optimal situation.
How do we get out of this situation?
One solution to remove these multiple connections is to create a single application that receives metrics data from all the applications out there. This application can act as the central hub for all metrics and provide a server to query those metrics for any system that needs them.
Of course, this solution does reduce the complexity of the architecture. But unfortunately, requirements always evolve.
Just like metrics, we may soon have the need for collecting log information and user activity information and so on. If we go by the above solution, we may end up building a separate central application for each use-case. In other words, we are maintaining multiple systems for doing the same job.
See below illustration that tries to depict the situation we end up creating.
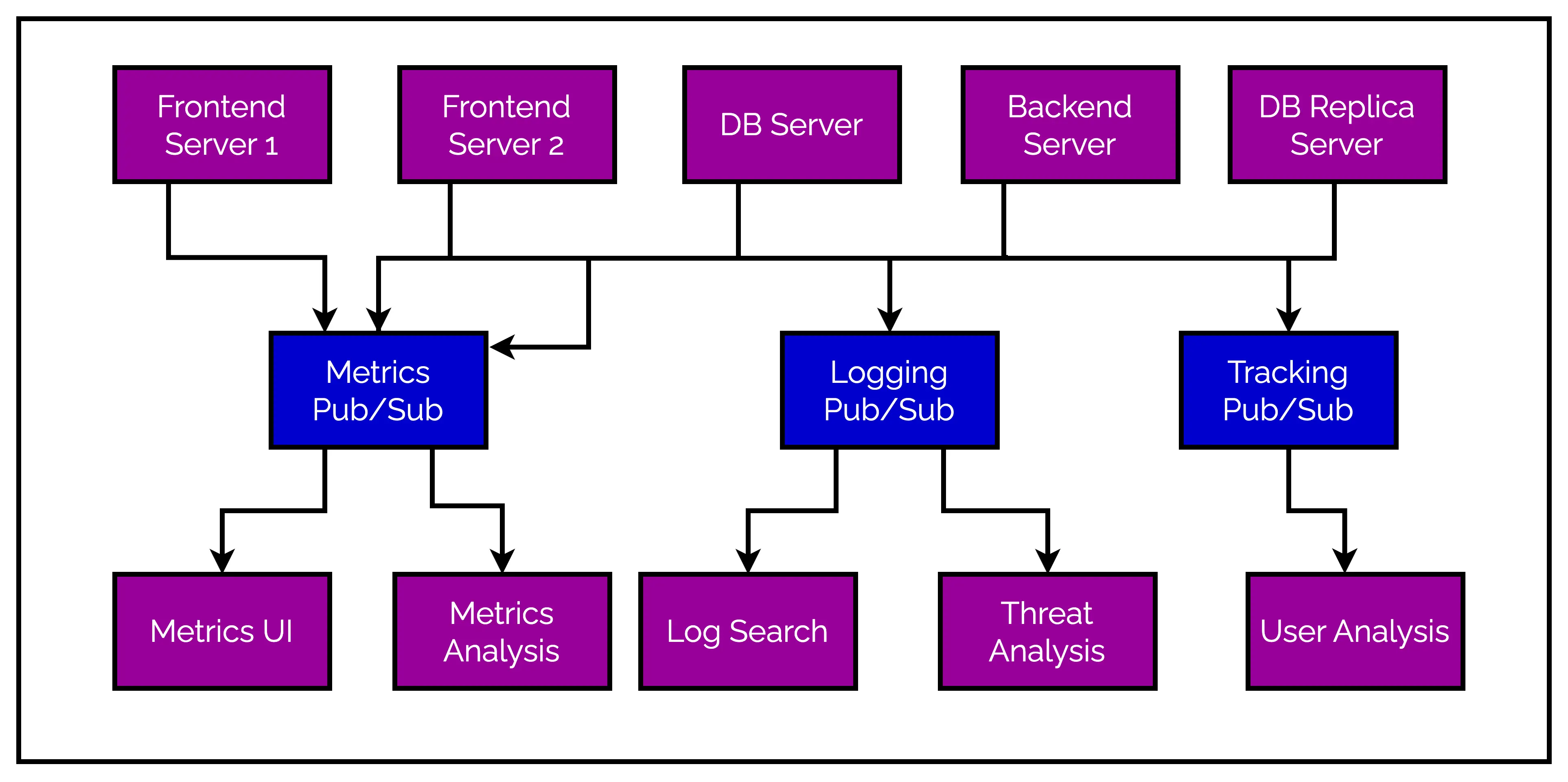
So – how do we untangle this mess?
We use publish/subscribe messaging pattern.
Basically, what we need to simplify things is a centralized system for publishing generic data to a large number of consumers. And Kafka happens to be that centralized system.
Kafka has been developed as publish/subscribe messaging system. By using Kafka, we can eliminate separate services to handle metrics, logs and user activity. Instead, Kafka can act as the single unified bridge between publishers and subscribers.
But Kafka is capable of many more things!
Apart from a pub/sub messaging system, Kafka also acts as a distributed commit log and more recently, a distributed streaming platform. Just like a filesystem or database commit log, Kafka stores data durably and in order. We can read the data deterministically.
INFO
Deterministically basically means that natural events or social phenomena can be causally determined by preceding events or natural laws. In the context of computer science, deterministic algorithm is one that gives the same output for a particular given input. The machine that executes the algorithm goes through the same set of states to arrive at the output.
3 – Kafka Messages and Batches
The basic unit of data in Kafka is called a message.
You can think of a message as a row or record in a database table. A message is simply an array of bytes and the data in the message has no specific meaning for Kafka.
Of course, for developers, it is important to have some sort of message structure. We can impose message schemas in Kafka using JSON or XML formats. Kafka favours the use of another tool known as Apache Avro for managing the schemas.
Messages are written to Kafka in batches. A batch is simply a collection of messages produced to the same topic and partition. Hold the two new terms (topic and partition) in your mind as we will get to them in a bit.
But why batches? Why not individual messages?
Because individual round trip of messages is excessive overhead. Collecting messages into a batch reduces this overhead. Batches are also compressed, providing efficient data transfer and storage.
Of course, using batches results in a trade off between latency and throughput. Larger the batch size means more messages per unit of time or increased throughput. However, it also means longer latency for an individual message. The ideal batch size depends on your specific use-case.
4 – Kafka Topics and Partitions
We briefly mentioned these terms in the previous section. These terms are probably the most important terms for Kafka developers. No Kafka introduction can happen without understanding these terms. Let us look at them one-by-one.
Kafka Topics can be compared to a database table or a folder in a filesystem. Basically, every message in Kafka is categorized into a particular topic.
Topics are also made up of multiple partitions. See the below illustration where we have a topic named numbers containing three partitions.
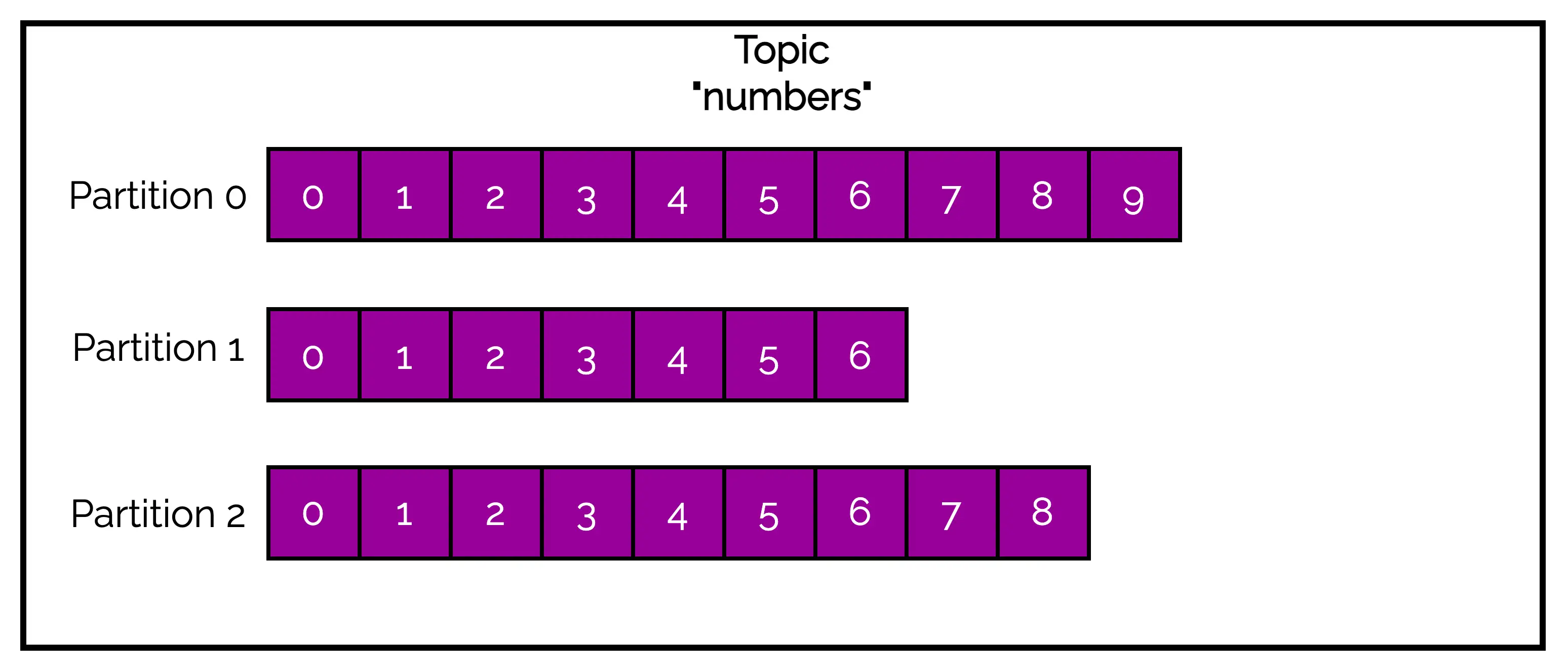
When we send a message to a Kafka topic, it is written to a partition in append-only manner. Since they are written this way, messages can be read in order from beginning to end.
However, this guarantee of ordering is only applicable within a particular partition. Since a topic can contain multiple partitions, there is no guarantee of message ordering across the entire topic.
Kafka partitions help provide redundancy and scalability. Each partition can be hosted on a different server (or a broker). This makes topics horizontally scalable and can provide performance far beyond the ability of a single server.
Additionally, we can also replicate partitions. This means a different server can store a copy of the same partition. Even if a server fails, the partition’s data is always available.
5 – Kafka Producers and Consumers
The main users of the Kafka system are also known as Kafka clients.
There are two basic types of clients – producers and consumers.
As the name suggests, producers create new messages and send them to a Kafka broker. We also call them publishers or writers. While sending a message, producers specify the topic. By default, producers will balance messages over all partitions of a topic evenly. Check out this post on how to create a Kafka Producer.
However, in some cases, the requirement is to send message to a particular partition.
But why would we want to do that?
A common scenario is when we want to preserve state changes of a particular entity throughout its lifecycle. Ordering of messages is important in such a case so that we can replay through each state change to arrive at the current state. But Kafka guarantees reading of messages in order only at the partition level (as we discussed in the previous section). Therefore, we need to make sure that messages belonging to a particular key always go to the same partition.
The simplest way to achieve this is to generate a consistent hash of the key. Then, we can select the partition number for that message by taking the result of the hash modulo the total number of partitions in the topic. This ensures that messages with the same key are always written to the same partition provided the partition count does not change. You can dive into this in more detail in our post on Kafka Custom Partitioning.
Once the messages are sent to Kafka, it is upto the consumers to read the messages. One or more consumers work together as part of a consumer group to consume a topic.
The consumer group ensures that each partition is only consumed by one member. Mapping of a consumer to a partition is often called ownership of the partition by the consumer.
See below illustration of a consumer group consuming messages from partitions. Here, each consumer is responsible for one partition in the topic.
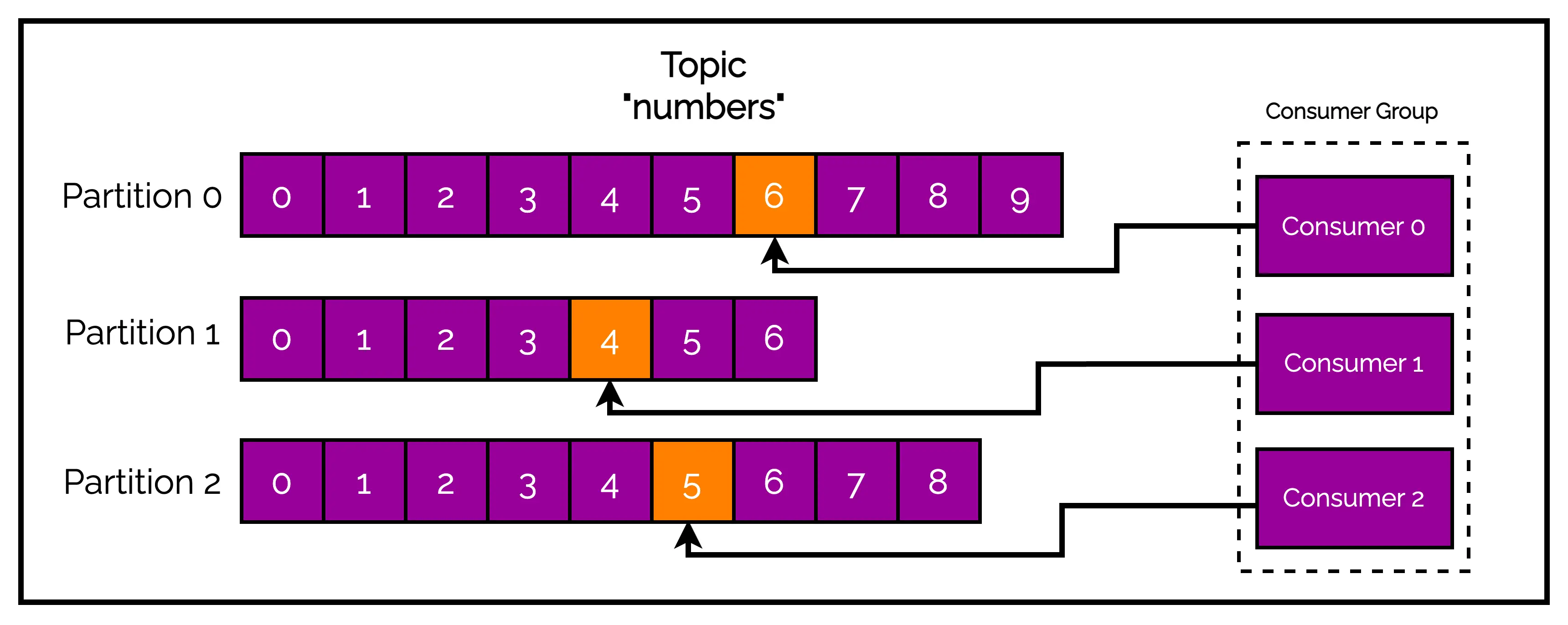
Consumers can horizontally scale to consume topics with a large number of messages. If a single consumer fails, remaining members of the group will reassign the partitions being consumed to take over for the missing member.
6 – Kafka Brokers and Clusters
A single Kafka server is called a broker.
The job of a Kafka broker can be divided into 3 parts on the producer side:
- Receive messages from producers
- Assign offset to these messages
- Write messages to storage on the disk
Similarly, it performs the below tasks on the consumer side:
- Handle the fetch requests for partitions
- Respond with the messages that have been published.
A single Kafka broker can handle thousands of partitions and millions of messages per second.
Moreover, Kafka brokers usually work as part of a cluster.
Basically, a Kafka cluster consists of several brokers. One of these brokers plays the role of the cluster controller. The cluster controller is elected automatically from amongst the live members of the cluster. This controller is responsible for various administrative operations such as:
- Assigning partitions to brokers
- Monitoring for broker failures
The main advantage of a Kafka cluster is the ability to replicate messages. Replication provides redundancy of messages stored in a partition.
A partition in Kafka is always owned by a single broker in the cluster. Basically, this broker is called the leader of the partition. However, when a partition is replicated, it is also assigned to additional brokers. These additional brokers are followers of the partition.
So, how do producers and consumers interact with a particular partition when there are several copies available across brokers?
Producers always connect to the leader broker to publish messages to a particular partition. If the leader broker goes down for some reason, one of the follower brokers takes leadership of the partition. On the other hand, consumers don’t have any such restrictions. They can fetch messages from either the leader or one of the followers.
The below illustration shows the relation between brokers, topics and partitions in the context of a Kafka cluster.
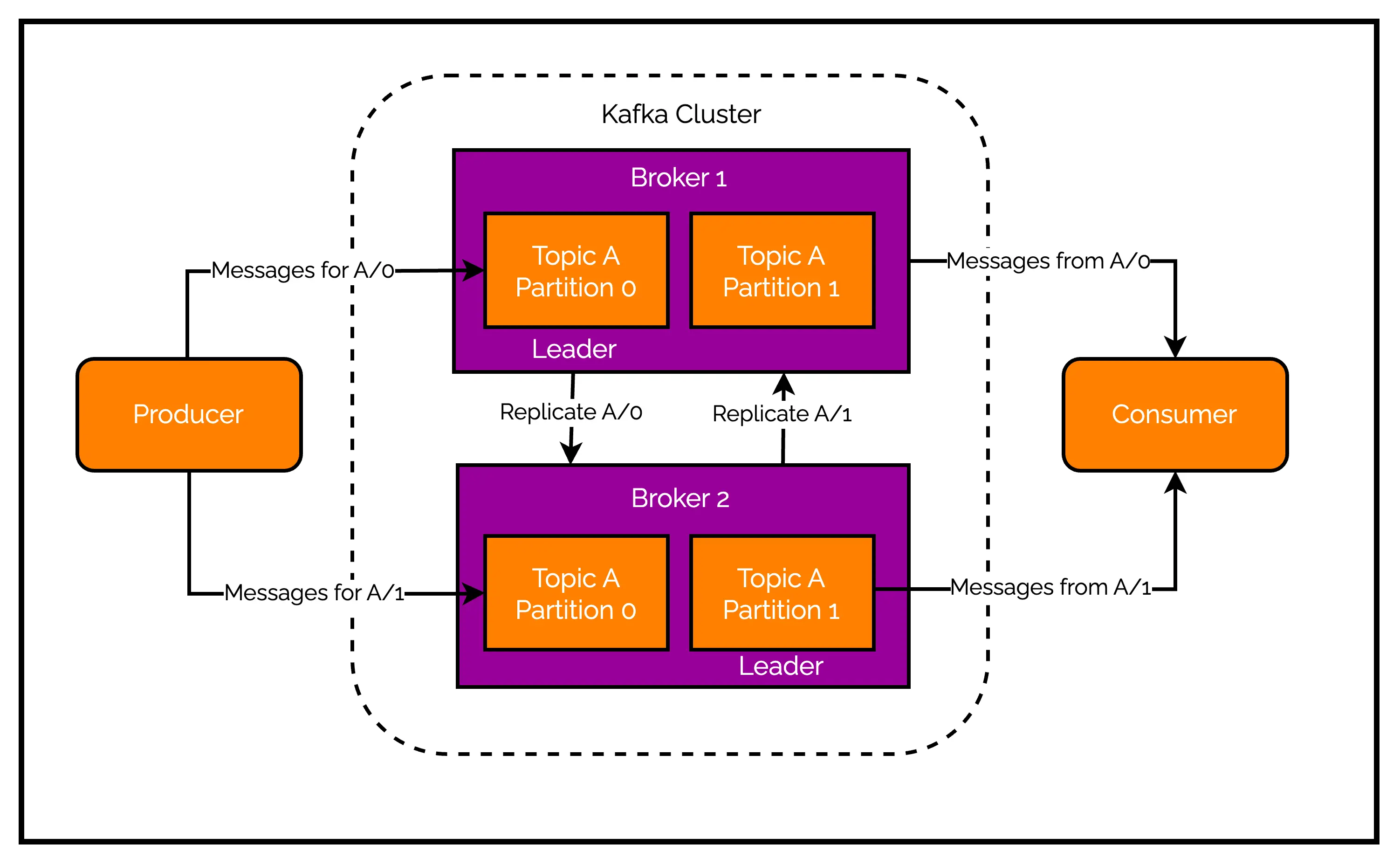
As you can see, Partition 0 of Topic A is replicated across Broker 1 and Broker 2. However, Broker 1 is the leader of the partition. Similarly, Broker 2 is the leader of the Partition 1 of Topic A. The Producer always writes to the leader broker.
7 – The Advantages of Using Kafka
Having understood the high-level components of Kafka, let us look at what makes it so special.
- Kafka can handle multiple producers with ease. We can use Kafka to aggregate data from many frontend systems and make it consistent in terms of format. For example, a site that serves content to users via a number of microservices can have a single topic for page views that all services can write to using a common format. Consumer applications can receive a single stream of page views for all applications on the site without having to co-ordinate across multiple topics.
- Kafka is designed to support multiple consumers reading a single stream of messages without interfering with each other’s client. This is unlike other queuing systems where once a message is consumed, it is not available to any other process. On the other hand, multiple Kafka consumers can also join together as a group and share a stream. In this case, the entire group processes a message only once.
- Kafka provides disk-based retention. Basically, messages are written to disk and stored with configurable retention rules. This means that consumers can afford to fall behind due to slow processing or spike in traffic. There is no danger of losing data. Another implication of disk-based retention is easy maintenance of consumers. If you need to take down a consumer, there is no concern about messages backing up on the producer or getting lost. The messages will be retained in Kafka. Consumers can restart and pick up processing right where they left off with no data loss.
- Kafka is highly-scalable. This makes it possible for Kafka to handle any amount of data. Users can start with a single broker for initial development and then move to a development cluster of three brokers. In a production setup, we can also have a larger cluster consisting of tens or even hundreds of brokers. Moreover, any expansion in capacity can be done even when the cluster is online without impacting the availability of the system.
8 – Disadvantages of Kafka
Just like everything else in software engineering, Kafka is by no means perfect. Some of the common gripes developers tend to have with Kafka are as follows:
- Kafka provides an overwhelming amount of configuration options. This makes things challenging for new comers as well as seasoned developers in terms of figuring out the optimal settings for the Kafka installation.
- The built-in tooling is sub-par. There is lack of consistency in the naming of command-line arguments.
- Lack of mature client libraries in languages other than Java or C. The libraries for other languages are not up to the mark in terms of quality.
- Lack of true multi-tenancy in terms of completely isolated logical clusters within physical clusters.
9 – Common Use Cases of Kafka
Lastly, let us also discuss some common use-cases of Kafka.
- Activity Tracking – This is one of the original use cases for Kafka from its LinkedIn origin days. In this case, the usual requirement is to track user activity on front-end applications. Based on user actions, messages are generated and sent to Kafka. We can collect passive information such as page views and tracking clicks. Also, we can collect information about complex actions such as updates to the user’s profile and so on. Once the messages are published to one or more topic, they can be consumed by applications on the backend. Using this information, other applications may generate reports, feed machine learning systems, update search results or perform other operations to provide a rich user experience. Basically, the sky is the limit.
- Messaging – Kafka also finds great use for messaging purpose. For example, applications may need to send notifications or emails to users. With Kafka, different applications can produce messages without getting concerned about formatting and dealing with email protocols. A single app can read all the messages and handle them in a uniform manner.
- Metrics and Logging – As we saw earlier, Kafka is also ideal for collecting application and system metrics and logs. Applications can publish their metrics to a Kafka topic. These metrics are consumed by systems for monitoring and alerting. Similarly, we can also publish log messages that are routed to dedicated log search systems like Elasticsearch. Even if we decide to change the destination log storage system in the future, there is no need to alter the frontend applications.
Conclusion
While there are many messaging systems such as RabbitMQ, ActiveMQ and so on, what makes Kafka unique is its all-round capability to handle a large number of scenarios and use-cases. In this Kafka introduction, we covered the various aspects of Kafka in great detail.
Moreover, Kafka brings certain important features to the table such as durability that make it a game-changer. Kafka is both simple to use for really small requirements but scales really well as the complexity of data and requirements increases.
0 Comments