Terraform works great with static configuration code to provision infrastructure. However, most real-world deployments need to be dynamic and depend on external data.
Terraform Data Source is a must-have ingredient to provision resources dynamically.
In this post, you get to learn everything about Terraform Data Sources with code examples.
- 1 – What is a Terraform Data Source?
- 2 – Terraform Data Source Example
- 3 – Why do we use Data Sources in Terraform?
- 4 – Terraform Data Sources vs Resources
- 5 – Data Source vs Importing a Resource
- 6 – Data Sources vs Locals vs Variables
- 7 – Terraform Conditional Data Source
- 8 – Terraform Data Source for_each example
- Conclusion
1 – What is a Terraform Data Source?
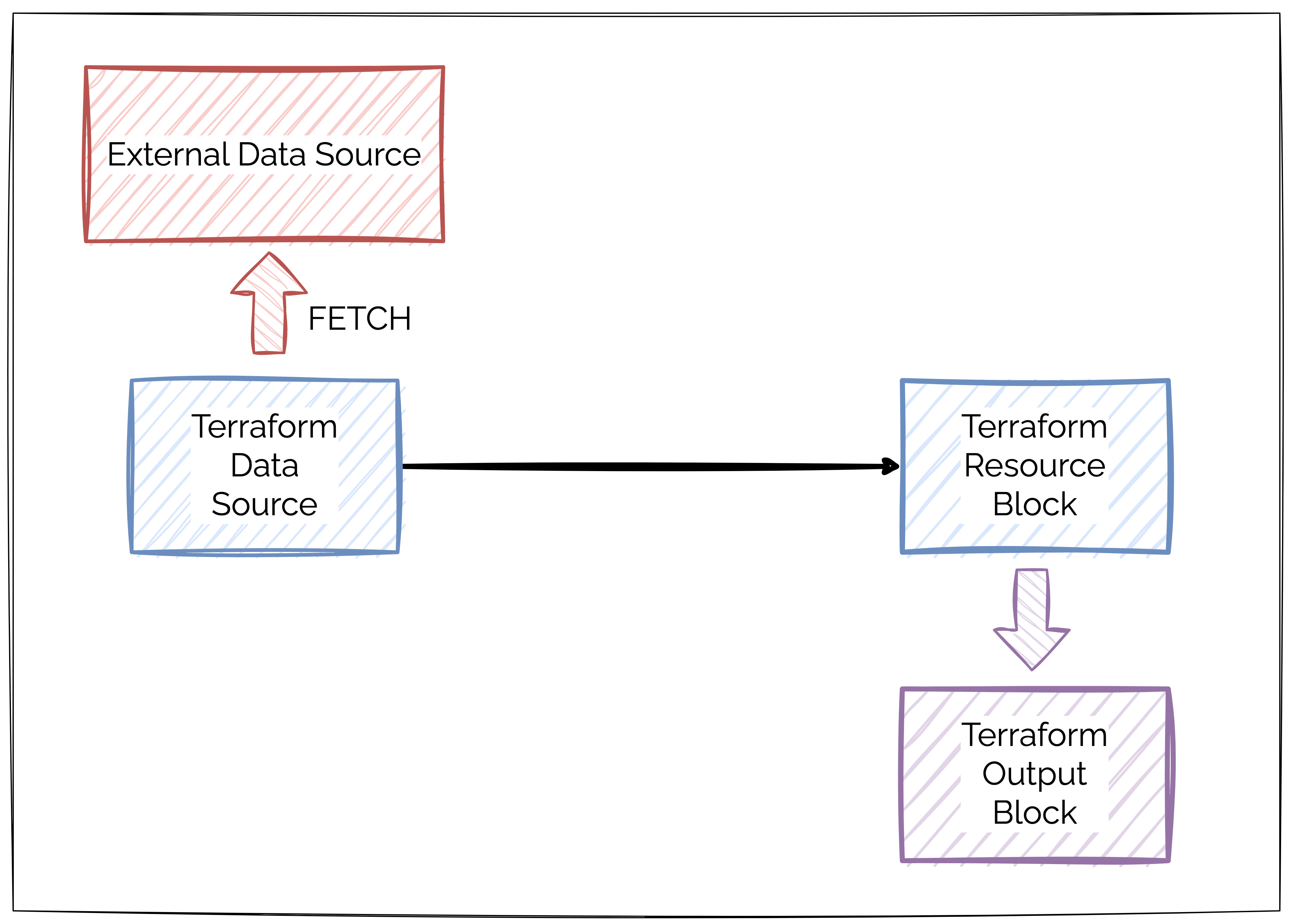
A Terraform Data Source lets you fetch information about resources that are outside of Terraform and use that information within the configuration.
What kind of information are we talking about here?
Basically, information that’s part of our infrastructure. It could be IP addresses of existing EC2 instances, details of S3 buckets, tags, other metadata and so on.
The role of a data source is to let you reference these resources in your infrastructure and use their properties in your Terraform code without manually specifying the values.
Check the below illustration to get a better idea.
2 – Terraform Data Source Example
Let’s take an example to drill down the usage of a Terraform data source
In an earlier post, we provisioned an AWS EC2 instance using a static Terraform configuration. Check out the below configuration snippet:
resource "aws_instance" "hello_aws" {
ami = "ami-0ceecbb0f30a902a6"
instance_type = "t2.micro"
tags = {
Name = "HelloAWS"
}
}
As you can notice, the AMI is hard-coded to a particular value. This may or may not be a smart idea.
What happens if newer versions of the AMI become available?
The Terraform configuration would be tied to the hard-coded older version that might have security vulnerabilities.
If you want to upgrade to the latest version, you’ll have to get the latest AMI Id from the AWS Management Console and plug it into the configuration. Again, that doesn’t sound like a very efficient thing to be done manually.
This is where you can use Terraform data source to make the configuration dynamic.
You can setup a data source to look up the latest value of the Ubuntu AMI available on AWS and use that to provision the EC2 instance.
Check out the below code from the main.tf file.
provider "aws" {
region = "us-west-2"
profile = "terraform-user"
}
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-*"]
}
owners = ["099720109477"]
}
resource "aws_instance" "hello_aws" {
ami = data.aws_ami.ubuntu.id
instance_type = "t2.micro"
tags = {
Name = "HelloAWS"
}
}
After the provider block, you basically declare a data source using the data block.
This block contains exactly two labels. The first label specifies the type of data source (in this case, “aws_ami”). The second label is the name of the data source.
Together, the type and name are referred to as the data source’s identifier and must be unique within a module.
The data block contains a bunch of arguments. These arguments are also known as query constraint arguments and basically specify the conditions to fetch data.
In this example, you are trying to fetch the most recent Ubuntu AMI by filtering all AMIs matching the regex expression ubuntu/images/hvm-ssd/ubuntu-focal-20.04-amd64-server-*.
Next, you make use of the data source within the resource block by setting the value of the ami to the data source data.aws_ami.ubuntu.id.
Applying the Configuration
You can apply the configuration by executing the terraform apply command.
data.aws_ami.ubuntu: Reading...
data.aws_ami.ubuntu: Read complete after 1s [id=ami-0d31d7c9fc9503726]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
If you inspect the output, you should notice that Terraform first fetches the AMI data according to the data source query and finds the id of the most recent AMI. Once it has the data, it continues further and creates the EC2 instance.
You can verify the changes by visiting the AWS console or running the terraform show command.
The source code for this Terraform data source example is available on Github.
3 – Why do we use Data Sources in Terraform?
There are several reasons to use Data Sources in Terraform:
- By using data sources, you can avoid hardcoding values of existing resources in your infrastructure.
- You can also automate the management of resources by using Terraform data sources. For example, consider a web application running on multiple EC2 instances where you want to enable incoming traffic on port 80. Instead of manual change, you can grab a reference to the EC2 instances using a data source and update the security group of the instances as per the requirement.
- Terraform data sources encourage code reusability. Let’s say you have multiple EC2 instances and you want to perform a couple of operations on these instances such as attaching them to an ELB or updating their security groups. You can simply create a data source block to retrieve information of all the EC2 instances and use the data source in other resource blocks such as ELB or Security Group Rule.
- Lastly, use of data sources in Terraform improves the readability of your code. You should give meaningful names to your data sources and stop relying on hard-coded values that can cause confusion as the code gets more complicated.
4 – Terraform Data Sources vs Resources
Developers often get confused between Terraform data sources and resources probably because they appear vaguely similar.
Though both are used to manage your infrastructure, they have different purposes:
- Terraform resources are used for creating, updating and deleting infrastructure resources. You use resources to define the desired state of your infrastructure and Terraform goes ahead and makes the desired state a reality.
- On the other hand, Terraform data sources are mainly used for querying information. Data sources are meant to retrieve information about existing resources in your infrastructure so that you can use that information in your Terraform code.
5 – Data Source vs Importing a Resource
So, are data sources in Terraform more like importing a resource?
Well, not exactly.
Importing a resource is the approach of bringing a manually created piece of infrastructure under the management of Terraform’s state. After importing, you are able to access the resource within the Terraform configuration file and perform operations upon it.
On a superficial level, this might sound quite similar to a Terraform data source.
And rightly so!
Importing a resource is a lot like pointing a data source at it. However, there are a few crucial differences:
- Firstly, the resource attached to a data source is meant for read-only. For example, you don’t want to go ahead and delete the AMIs hosted by AWS using a data source. When you import a resource, Terraform can actually destroy it using
terraform destroycommand. - Second, importing a resource brings it within Terraform’s active management. Therefore, even if you delete the imported resource manually, Terraform will see it as a drift in configuration and attempt to re-create the resource when you execute
terraform apply.
Before deciding whether to use a data source or import a resource in Terraform, think about what you are trying to do with it. If you just need access to the properties of the resource, it is better to use a Terraform data source.
If you want to know more, check out this detailed post on importing an existing EC2 instance to Terraform.
6 – Data Sources vs Locals vs Variables
If you are new to Terraform, chances are that you might also get confused between data sources, locals and variables.
Here’s a quick run down of the three terms:
- Your familiar data source takes in data from the outside world and makes it available within the Terraform configuration
- Variables are used to load data from a parent module or the process running a Terraform configuration. You use variables to pass in run-time information that helps your configuration run properly
- Lastly, Terraform locals are used to define reusable values or expressions within your Terraform code. You define them using the
localsblock. Though they seem quite similar to variables, the major difference is the scope. Terraform locals are restricted to a specific module and are only accessible within the module they are defined in.
7 – Terraform Conditional Data Source
Data sources in Terraform are quite versatile in the way you can use them.
For example, Terraform conditional data source can help you reference different data sources based on certain conditions. A great use-case for this feature is to create dynamic infrastructure based on the environment (such as development or production).
Here’s an example of creating a conditional data source that determines whether to use the production or development S3 bucket based on the “environment” variable.
resource "aws_s3_bucket" "dev_bucket" {
bucket = "dev-bucket"
}
resource "aws_s3_bucket" "prod_bucket" {
bucket = "prod-bucket"
}
data "aws_s3_bucket" "example" {
bucket = var.environment == "production" ? aws_s3_bucket.prod_bucket.bucket : aws_s3_bucket.dev_bucket.bucket
}
variable "environment" {
type = string
default = "development"
}
If interested, you can check out our detailed post on Terraform conditional data source and its usage.
8 – Terraform Data Source for_each example
Another use-case for Terraform data source is the ability to iterate over a bunch of similar resources.
You can use the Terraform Data Source for_each argument to perform some common operation on a group of similar resources such as EC2 instances, RDS instances and so on.
Check out this simple example where you output the ip_addresses and tags for 3 EC2 instances declared using the instances variable. The data source uses for_each to specify a list of instances that the data source should retrieve information for and makes it available as a reference.
variable "instances" {
type = map(string)
default = {
"i-01234567890abcdef0" = "web-server-1"
"i-01234567890abcdef1" = "web-server-2"
"i-01234567890abcdef2" = "web-server-3"
}
}
data "aws_ec2_instance" "example" {
for_each = var.instances
instance_id = each.key
}
output "ip_addresses" {
value = [for instance in data.aws_ec2_instance.example : instance.public_ip]
}
output "tags" {
value = [for instance in data.aws_ec2_instance.example : instance.tags]
}
If interested, you can check out this super-detailed post on practical applications of Terraform data source using for_each.
Conclusion
To conclude things, Terraform Data Source is a must-have ingredient if you want to streamline your infrastructure management.
Data sources provide several valuable features to make your Terraform code more manageable in the long run.
If you liked this post or found it useful, consider sharing it with friends and colleagues. In case of any queries, please write them in the comments section below.
3 Comments
Anonymous · February 1, 2023 at 2:24 pm
Great article ! Thank you so much !
NE · February 1, 2023 at 2:25 pm
Great article ! Thanks !
Saurabh Dashora · February 3, 2023 at 1:58 am
Glad you liked it!