As the complexity of software application increases, we also need better tools to manage the complexity. GraphQL is one such tool that brings a paradigm shift in the way clients and servers interact. In this post, we will get a detailed Introduction to GraphQL and understand what makes GraphQL so special.
1 – What is GraphQL?
GraphQL was developed by Facebook for one of their internal projects and eventually open-sourced. It stands for Graph Query Language. However, this can mislead us a little bit. While it is a query language, it is not used to interact directly with the database like SQL (or Structured Query Language).
So what do we query using GraphQL?
Well – we don’t exactly query anything directly using GraphQL. It’s not like writing a SQL statement and executing it on the shell to fetch some results from a database. Instead, we use GraphQL as a format to define the contract between the client and the API server.
INFO
GraphQL is an open-standard. This basically means that there is no official implementation of GraphQL. Instead, we can create a GraphQL implementation using any programming language. The only caveat is that it should follow the specifications of GraphQL. Apollo GraphQL is one such popular implementation.
With this piece of information, you can also think of GraphQL as a specification. Some people also like to call it a new API standard similar to REST. In fact, it is often considered more efficient and flexible when compared to REST.
To make matters simple, we can use GraphQL where we were normally using REST. In a way, it does what REST has been doing for all these years.
2 – Features of GraphQL
There are some important features of GraphQL that give it a particular identity and are important for a solid introduction.
2.1 – Declarative
This is probably one of the most important aspects of GraphQL.
In GraphQL, client specifies the fields it is interested in and the GraphQL server will make sure that only those fields are returned as part of the response.
Let us see what that means.
{
book(id: "1") {
title
publishYear
price
}
}The above is an example of a typical GraphQL query. As you can see, the query is pretty simple to understand. It is asking for details of the book having id 1. However, the only fields needed are the title, publishYear and price.
The response to this query could be a JSON object as below:
{
"data": {
"book": {
"title": "The Eye of the World",
"publishYear": 1990,
"price": 12.99
}
}
}This is totally different from REST where client has no control over the shape of the response. However, GraphQL only provides the exact information that is needed.
2.2 – Hierarchical
Queries in GraphQL are hierarchical.
What does it mean?
Let’s understand by extending our earlier example.
{
book(id: "1") {
title
publishYear
price
authors {
name
country
}
}
}In the above query, we are also asking for the authors of the book. The response will be as below:
{
"data": {
"book": {
"title": "The Eye of the World",
"publishYear": 1990,
"price": 12.99,
"authors": [
{
"name": "Robert Jordan",
"country": "USA"
}
]
}
}
}Apart from the book details, we also get an embedded object that contains the list of authors. In this case, there was only one author.
Important point to note here is that the books and authors might be stored in completely different database tables. It does not matter to GraphQL. A single GraphQL request fetches both and returns the response to the client.
2.3 – Type Safety
GraphQL is strongly-typed. It has a particular type system. Each type describes the kind of value that can be stored.
There are common primitive types such as numeric integers, booleans or strings. However, there are also complex types such as objects.
See below example:
type Book {
title: String!
publishYear: Int
price: Float
}Here, we have a Book object with fields containing String, Int and Float scalar types. This is also known as a GraphQL Schema. A schema helps the server determine whether the incoming query is valid. You can read more about GraphQL Schemas in this post since it will make the introduction more lengthy than necessary.
3 – Architecture of GraphQL-Based Application
From an architectural perspective, GraphQL comprises of two main parts – server and client. It is also a key part of the GraphQL introduction.
A GraphQL server basically implements the GraphQL specifications. It can be written in any programming language as long as the specs are followed.
The job of the server is to expose the API capabilities. Usually, there is a single endpoint /graphql that clients can use to send queries and receive responses. GraphQL is also database-agnostic. We can use SQL as well NoSQL databases along with GraphQL. In fact, data source can also be an aggregation of typical REST endpoints.
GraphQL belongs to the application layer and acts as an interface between the client and the data. Being a part of the application layer, it is also transport agnostic. As a result, it can be served over any protocol. However, the usual choice is HTTP.
Clients have more control in a GraphQL architecture. They make requests to the GraphQL server. These requests are also known as documents. A request can be a query (for reading data) and mutations (for writing data). While querying, the clients only request for the data they need.
There are more aspects to consider on the architecture front. You can refer to this post for more details about it.
4 – GraphQL Comparison With REST
Over the past many years, REST has been a de-facto standard to build APIs. REST brought some great concepts to the table such as stateless services and resources. However, REST APIs have also been found to be inflexible to changing requirements of the clients.
Below are some of the aspects to consider while comparing GraphQL with REST. Without this, our introduction to GraphQL would be incomplete.
4.1 – Over-Fetching or Under-Fetching Data
A common problem in REST is over-fetching or under-fetching of data. This is because each endpoint has a specific layout. Whether the client needs it or not, the endpoint will return the entire data structure.
See below illustration that tries to visualize the process of data-fetching in a typical REST architecture.
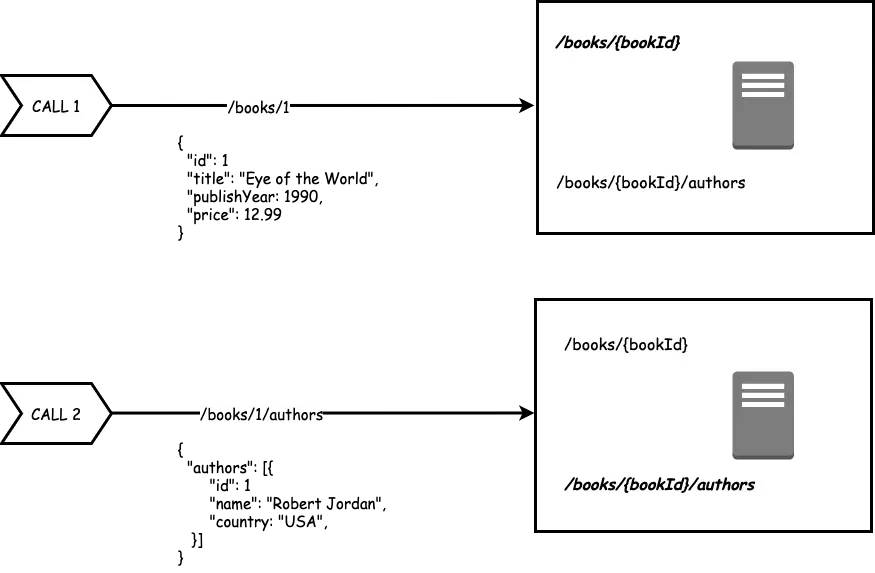
Over-Fetching happens when the client receives more information than what it needs to show on the app. Taking for book example, if one of the screens only needs to display the name of the book, it will still get the entire book data (such as price, genre, publication year) from the Book API. All of that information is practically useless for the client. Apart from increasing the code complexity, this also causes more data transfer over the network.
Under-Fetching is the other end of the problem. This happens when a particular endpoint has less information than needed. For example, if we wish to show the name of the book and author name, it may be the case that the book endpoint does not return the author name and we have to make a request to another REST endpoint to get the same. This can indirectly lead to an escalation where a client has two make multiple requests to build a particular view. It also causes n+1 request problem.
In GraphQL, both of these problems do not occur as the control of the query shifts to the client. See below illustration:

4.2 – Network Traffic
As seen in our discussion, REST APIs can lead to multiple inefficient calls to receive a set of data. On the other hand, in GraphQL, the same thing is possible in a single call using hierarchical queries.
This indirectly saves network bandwidth as well as reduces the overall traffic in terms of the number of API calls.
4.3 – Better Backend Analytics
With REST APIs, it is not possible for the server to know what kind of data the client is using. It has the information on a high-level but not on a field-level.
With GraphQL, each client specifies exactly what it needs. This information is extremely useful from a business analytics point of view. In the long run, it can help the backend developer improve their API offering to suit the client needs.
4.4 – Error Handling
One important distinction between REST and GraphQL is in the error handling aspect. Though it is common to have GraphQL also use HTTP, it is not a mandatory condition. Therefore, the standard HTTP error codes do not apply to GraphQL.
Due to this reason, GraphQL endpoints usually return a 200 status code. Failed requests will include a specific errors property along with the data property. This is quite different from REST APIs where status codes also play an important role in the API response.
5 – Conclusion
We have covered the major points surrounding GraphQL in this introduction. However, GraphQL is a vast topic.
If interested to know more, you can check out this post on the core concepts of GraphQL. Also, if you are looking to get started with actual coding, you can check out this post on creating a GraphQL API Server.
If you have any comments or queries about this post, please mention them in the comments section below.
2 Comments
Yogesh Nerkar · July 14, 2023 at 3:53 am
Thank you Saurabh for the informative details on GraphQL. Do you have any template (free to download) to prepare API technical specifications using GraphQL for applications?
Saurabh Dashora · July 18, 2023 at 1:01 am
Thanks for the great feedback Yogesh.
Unfortunately, I have not written much more on GraphQL after that…