Data is the backbone of every organization out there. Ensuring that your data is always available is probably the most important consideration for any business.
If the application’s data is not available when customers need it, chances are that they won’t be your customer much longer.
This is where Database Replication comes into play.
It’s likely that the term comes from the concept of DNA replication which forms the basis of inheritance in biological organisms.
Either way, database replication is a backend developer’s BFF.
In this article, I will explain the concept of database replication, its benefits, common use cases, working mechanisms, types, and the challenges associated with it.
Whether you’re a backend developer, an architect, or simply curious about databases, this article will provide you with a comprehensive understanding of database replication.
1 – Understanding Database Replication
So what’s database replication?
If I had to explain to my non-tech family member, I’d say database replication is like keeping a copy of your data in different places.
On a more formal level, database replication refers to the process of creating and maintaining duplicate copies of a database across multiple servers.
These copies, known as replicas, are synchronized with each other. This ensures that any changes made to the original database are propagated to the replicas.
The constant synchronization maintains data consistency as well as keeps your data available when something goes wrong.
Here’s a basic illustration to drive home the point.
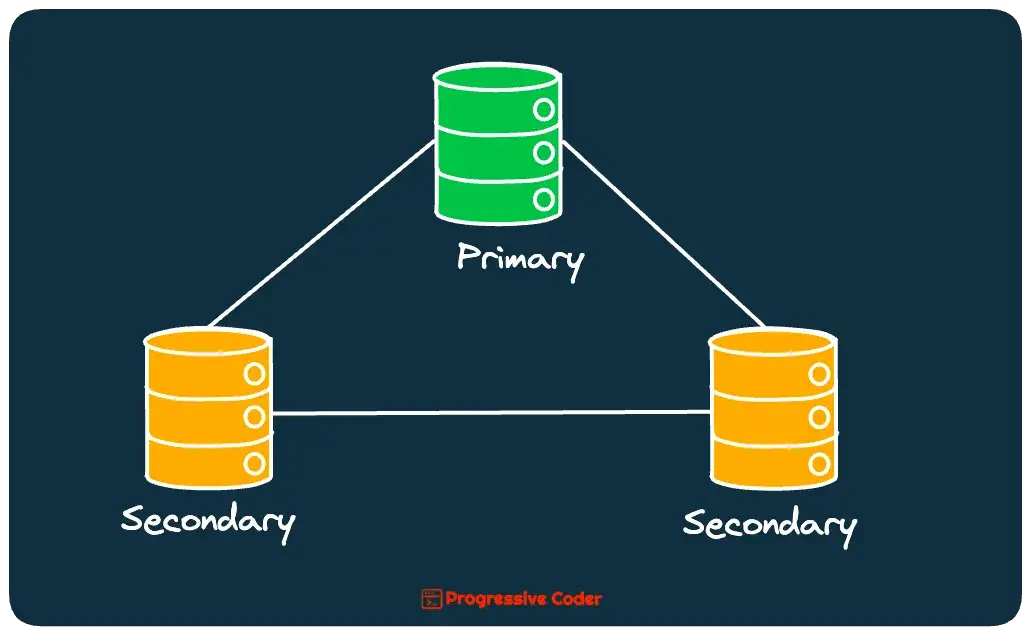
2 – Benefits of Database Replication
Why would anyone want to use database replication?
That’s because of some amazing benefits:
- First off, it greatly enhances data availability and accessibility of your data. Multiple replicas spread geographically across different servers let the users access data from the replica closest to them. This reduces latency and improves response times. Moreover, if a server goes belly up, the replicas act as backups to safeguard the data.
- Database replication enhances data security and disaster recovery. You can create offsite replicas of your data to protect your data from catastrophic events like hardware failures, natural disasters, or something like a Godzilla attack. After all, you need to run your business no matter what happens.
- Furthermore, database replication facilitates scalability and load balancing. By distributing the workload across multiple servers, organizations can handle increasing amounts of data and user traffic without compromising performance. This scalability is especially vital for high-traffic websites and e-commerce platforms.
3 – Common Use Cases for Database Replication
OK, so you might be convinced of the benefits.
But you can’t think of any applications where database replication is useful.
Let me fix that for you.
Here are a couple of examples:
- Firstly, high-traffic websites and e-commerce platforms are intoxicated to database replication to meet the demands of a large user base. With the cheat code of distributing the load across replicas, these platforms can handle thousands of concurrent users. All of it without experiencing performance bottlenecks.
- Database replication lets you spread your data across multiple locations. Think of a streaming service like Netflix that has users in every single part of the globe. Now imagine all of those users streaming their favorite movie from a data center in North America. Catastrophe. By replicating the database, users can access the data from the replica that’s closest to them.
4 – How does Database Replication work?
The below diagram shows the most common approach to Database Replication.
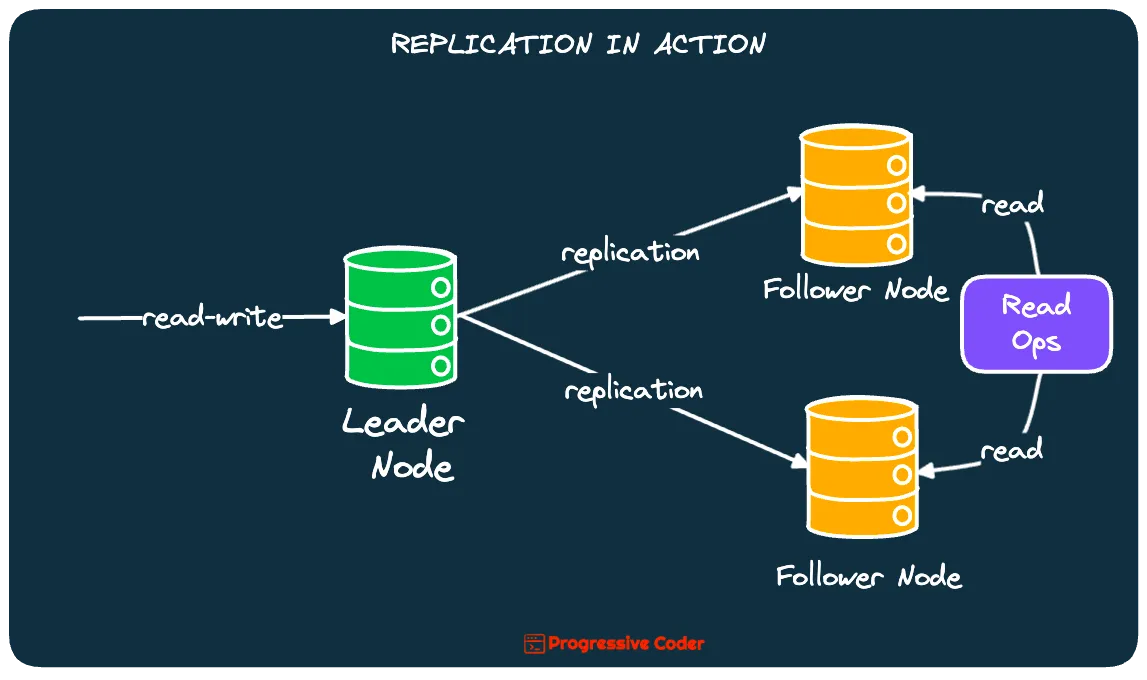
Each node or instance that stores a copy of the data is known as a replica. In the illustration, we have 3 replicas – 1 green and 2 yellow.
Every write to the database should reach every replica. Otherwise, there’s no point in replication.
The most common approach to get this done is Leader-Based Replication. You may know it by other names such as Active/Passive or Master-Slave Replication. All of them are basically the same thing.
In the figure, the green replica is the Leader node while the others are Followers.
Here’s what happens under the hood.
- In this style of replication, clients send all their write requests to the leader node. The leader writes the new data to its local storage.
- The leader also sends the data change to all its followers in the form of a replication log or change stream.
- Each follower reads the log and updates its local copy of the database to bring it up to speed.
- When a client wants to read data from the database, it can send the query to the leader or any of the followers as well. This is usually done automatically using load balancers.
Leader-based replication may sound intimidating. But modern database systems abstract it for the clients. PostgreSQL, MySQL, MongoDB, and other databases all have replication as an in-built feature.
In fact, distributed message brokers such as Kafka and RabbitMQ also provide this capability out of the box.
5 – Types of Replication
There are two main types of replication:
- Synchronous
- Asynchronous
In Synchronous Replication, the leader waits until all followers have confirmed that they have received the write before reporting success to the user.
In Asynchronous Replication, the leader sends the updates to the followers, but does not wait for a response from the follower.
As you can notice, synchronous replication guarantees that followers will have an up-to-date copy of the data. However, this comes at the cost of the whole system going down even if one follower goes down.
Asynchronous replication gets around this issue by making the leader free to process new write operations. However, this comes at the cost of a write operation not guaranteed to be durable even if it has been confirmed to the client.
Ultimately asynchronous replication can also lead to the problem of eventual consistency. But more on that in a later post.
6 – Common Challenges with DB Replication
Nothing is completely sacred in distributed systems.
Everything is a trade-off and so is database replication.
While database replication offers many game-changing benefits, it’s not without its challenges.
- One common issue is replication lag, where the replicas fall behind the primary database due to network latency or resource constraints. This is a big problem in applications where updates are frequent. Identifying and addressing replication lag requires a bunch of monitoring tools.
- Maintaining data consistency and integrity is another challenge. Data conflicts and inconsistencies may arise when updates occur simultaneously on different replicas. Implementing data validation and verification mechanisms, such as timestamp-based conflict resolution, helps mitigate these challenges.
- Failover and disaster recovery considerations are also crucial. Planning for failover scenarios and ensuring robust disaster recovery processes are essential.
Conclusion
In conclusion, database replication is a vital component of modern data management strategies.
With the right implementation, it can dramatically improve the data availability and scalability of your application.
But you should not treat is as an after-thought while implementing. Though many databases provide replication as a feature, you can’t leave everything to just flipping a button.
Remember to have proper mitigation strategies in case something goes wrong.

0 Comments